[Matplotlib超入門:pyplot編]DataFrameから箱ひげ図を描く方法と、pandas搭載のグラフ機能との比較:Pythonデータ処理入門
箱ひげ図ってうまく使うと便利ですよね。でも、Matplotlibとpandasでは箱ひげ図をプロットする方法が幾つもあるんです。その辺を中心に、Matplotlibでグラフを描くのか、pandasでやるのか。そんなことを考えてみましょう。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
なお、【Matplotlib超入門:pyplot編】では以下のバージョンを使用しています。
- Python 3.13
- Matplotlib 3.10.3
今回の内容
今回はMatplotlib(のpyplotインタフェース)を使って、pandasのDataFrameオブジェクトを可視化する方法について見ていきます。MatplotlibにDataFrameオブジェクトを渡す方法もあれば、DataFrameオブジェクトやSeriesオブジェクトのメソッドを使って、Matplotlibにグラフを書いてもらう方法もあります。以下では箱ひげ図の描画を中心にそれらのやり方について紹介しましょう。
なお、以下ではMatplotlibのpyplotインタフェースやNumPy、pandasをインポートする以下の行を実行してあるものとします。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pandasのデータをpyplotで可視化するには
Matplotlibはグラフ描画の際にNumPyのndarray(多次元配列)などを入力として受け取ることを前提としています。例えば、以下はこれまでの回でも見てきたサイン関数のグラフを描画するものです(実行結果は省略)。
def plot_sine_curve():
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.plot(x, y)
plot_sine_curve()
plt.show()
ここではグラフのX座標とY座標の値にNumPyのndarrayを使用しています。しかし、MatplotlibではpandasのDataFrameオブジェクト(やSeriesオブジェクト)を使ったグラフの描画も可能です。
def plot_sine_curve():
x = np.linspace(0, 10, 100)
y = np.sin(x)
df = pd.DataFrame({'x': x, 'y': y})
plt.plot(df['x'], df['y'])
plot_sine_curve()
plt.show()
Visual Studio Codeこのコードを実行すると、以下のようにサイン関数のグラフが描かれます(以下同じ)。

このように、多くの場合はMatplotlibにpandasのDataFrameオブジェクトを渡して、そのデータを可視化できます(DataFrameにテキストデータが含まれていたり、異なる型の数値データで構成されていたりするときには注意が必要でしょう)。その一方で、DataFrameオブジェクト(やSeriesオブジェクト)が持つplot属性(呼び出し可能オブジェクト)やboxplotメソッド、histメソッドなどを使っても可視化が可能です。以下ではこれらについて簡単に紹介していきます。
MatplotlibにDataFrameオブジェクトを渡す
上でも見た通り、多くの場合、MatplotlibにはDataFrameオブジェクトやSeriesオブジェクトを渡してグラフを描画できます。第1回では、以下を紹介しました。
DataFrameオブジェクトやSeriesオブジェクトを渡して、これらのグラフが描画できることは手元で確認したので、以下では例として箱ひげ図を描画してみることにします。
pyplot.boxplot関数
pyplot.boxplot(x, *, orientation='vertical', labels=None)
xに与えたデータの箱ひげ図をプロットする。主なパラメーターは以下の通り(一部抜粋)。
- x:箱ひげ図のプロット対象のデータ。2次元のデータであれば列ごとに箱ひげ図が描画される。リストなどに1次元のデータが要素として含まれている場合は、要素ごとに箱ひげ図が描画される
- orientation:箱ひげ図を縦に描くか('vertical')、横に描くか('horizontal')を指定する。省略時には'vertical'が指定されたものとして扱われる
- tick_labels:箱ひげ図のラベル。省略時は1、2、3、……のように順番に表示される
簡単な例を以下に示します。
np.random.seed(42)
data0 = np.random.normal(loc=5, scale=3, size=100)
data1 = np.random.normal(loc=10, scale=7, size=100)
data2 = np.random.normal(loc=15, scale=5, size=100)
df = pd.DataFrame({'data0': data0, 'data1': data1, 'data2': data2})
plt.boxplot(df, orientation='vertical', tick_labels=df.columns)
plt.show()
このコードでは平均値と分散が異なる正規分布のデータを作成し、それらをDataFrameオブジェクトにまとめたものをpyplot.boxplot関数に渡しています。orientationパラメーターには'vertical'を、tick_labelsパラメーターにはdf.columns(各列の列名)を指定しているので、箱ひげ図が縦方向に描かれ、それらのラベルとして各列の名前が使用されます。
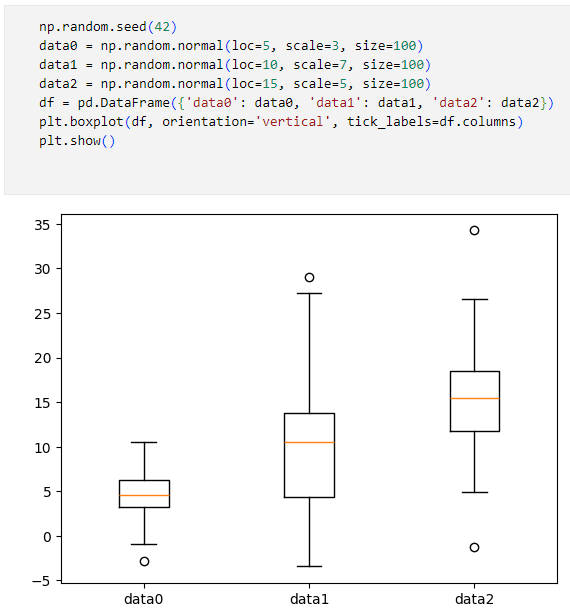 実行結果
実行結果より細かく制御したいのであれば、中央値の信頼区間を表すノッチを表示したり(notch=True)、箱やひげの属性(線色など)を指定したりすることも可能です。以下に例を示します。
np.random.seed(42)
data0 = np.random.normal(loc=5, scale=3, size=100)
data1 = np.random.normal(loc=10, scale=7, size=100)
data2 = np.random.normal(loc=15, scale=5, size=100)
df = pd.DataFrame({'data0': data0, 'data1': data1, 'data2': data2})
boxprops=dict(facecolor='lightblue', edgecolor='black')
plt.boxplot(df, orientation='horizontal', tick_labels=df.columns,
notch=True, patch_artist=True, boxprops=boxprops, showmeans=True)
plt.show()
このコードでは、orientationを'horizontal'として横向きに箱ひげ図を表示するようにすると共に、以下のパラメーターを指定しています。
- notch=True:ノッチを表示
- patch_artist=True:箱の部分を単なる線画(MatplotlibのLine2Dオブジェクト)ではなしにPatch(塗りつぶし色と境界線色などの属性を持つMatplotlibのオブジェクト)を使うことを指定
- boxprops=boxprops:箱の描画に使用する属性を辞書で指定(dict(facecolor='lightblue', edgecolor='black'))。boxpropsパラメーター自体はpatch_artist=Trueでなくても指定可能(このときには塗りつぶし色は指定できない。例:dict(color='blue', linewidth=1.5))
- showmeans=True:各箱ひげ図に平均値を表すシンボルを表示
コードを実行すると、次のようになります。

この他にも外れ値の表示/非表示の指定、その描画属性の指定、ひげの描画属性の指定など、カスタマイズできる要素がたくさんあります。詳しくはMatplotlibの公式ドキュメント「matplotlib.pyplot.boxplot」を参照してください。
なお、pandasのDataFrameオブジェクトには同様な処理を行うboxplotメソッドが、そしてDataFrame.plot属性にも同様な処理を行うDataFrame.plot.boxメソッドがあります(後述)。
DataFrame/Seriesオブジェクトが持つplotメソッドを使う
今も少し触れましたが、DataFrameオブジェクト(およびSeriesオブジェクト)にはplot属性があります。これは呼び出し可能なオブジェクトであり、「df.plot(……)」のようにすることでグラフを描画できます。が、plot属性にはさらにメソッドが用意されていて、それらを個別に呼び出すことも可能です。
以下はメソッドのように呼び出す場合のDataFrame.plot属性の書式です(一部抜粋。Seriesオブジェクトでも使用可能)。
DataFrame.plot属性
pandas.DataFrame.plot(x, y, kind='line')
バックエンドを使用して(デフォルトはMatplotlib)呼び出しに使用したDataFrameを可視化する。主なパラメーターは次の通り。
- x:X軸の値として使用する列の指定(ラベルもしくは数値)
- y:Y軸の値として使用する列の指定(ラベルもしくは数値)
- kind:描画するグラフの種類
kindパラメーターには以下を指定可能。
| 値 | グラフの種類 | Matplotlibの対応する関数 |
|---|---|---|
| 'line' | 折れ線グラフ | pyplot.plot |
| 'bar' | 垂直棒グラフ | pyplot.bar |
| 'barh' | 水平棒グラフ | pyplot.barh |
| 'hist' | ヒストグラム | pyplot.hist |
| 'box' | 箱ひげ図 | pyplot.boxplot |
| 'kde' | KDE(カーネル密度推定)グラフ | ×(内部でSciPyを使用) |
| 'density' | 'kde'と同じ | × |
| 'area' | 積み上げ折れ線グラフ | × |
| 'pie' | 円グラフ | pyplot.pie |
| 'scatter' | 散布図 | pyplot.scatter |
| 'hexbin' | 六角形ビンプロット | pyplot.hexbin |
| kindパラメーターに指定可能な値 | ||
kindパラメーターに指定可能な値のうち、Matplotlibの側では対応する関数を提供していないものもある点には注意してください。また、Matplotlibが提供する関数とDataFrameオブジェクトが持つメソッドが全く同じ機能になっているわけでもありません(後述)。
DataFrame.plot属性は呼び出し可能オブジェクトなので、次のようにして呼び出すことでグラフを描画できます。ここでは散布図と似た、しかし各点をプロットするのではなく、グラフ上を六角形で区切って、個々の六角形に含まれる点の密度を色の濃さで示す形式のグラフである「六角形ビンプロット」(kind='hexbin')を使ってみます。
num = 1000
np.random.seed(2)
x = np.random.normal(loc=3.0, scale=1.0, size=num)
y = np.random.normal(loc=4.0, scale=1.0, size=num)
df = pd.DataFrame({'x': x, 'y': y})
df.plot(kind='hexbin', x='x', y='y', gridsize=10)
plt.xlim(0, 8)
plt.ylim(0, 8)
plt.show()
実行結果を以下に示します。
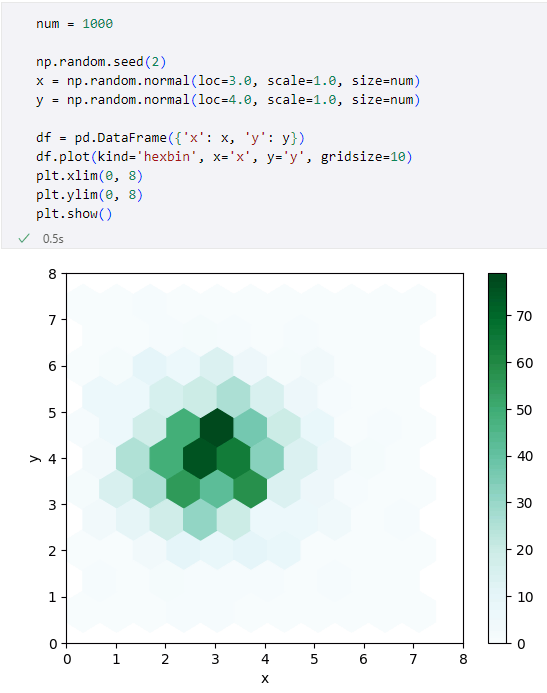 六角形ビンプロットの描画
六角形ビンプロットの描画このようにkindパラメーターで描画するグラフを指定可能な一方で、DataFrame.plot属性にはkindパラメーターに指定可能な値に対応した以下のメソッドがあります。
| メソッド | グラフ |
|---|---|
| DataFrame.plot.line | 折れ線グラフ |
| DataFrame.plot.bar | 垂直棒グラフ |
| DataFrame.plot.barh | 水平棒グラフ |
| DataFrame.plot.hist | ヒストグラム |
| DataFrame.plot.box | 箱ひげ図 |
| DataFrame.plot.kde | KDEグラフ |
| DataFrame.plot.density | kdeメソッドと等価 |
| DataFrame.plot.area | 積み上げ折れ線グラフ |
| DataFrame.plot.pie | 円グラフ |
| DataFrame.plot.scatter | 散布図 |
| DataFrame.plot.hexbin | 六角形ビンプロット |
| DataFrame.plotメソッドのkindパラメーターに対応するメソッド | |
なお、Matplotlibで描画可能な他のグラフを、DataFrame.plotメソッドで描画することはできません。例えば、「df.plot(kind='violin', ……)」のようにしてバイオリン図を描画することはできません。上に挙げたものは、pandasを使うことに集中して、DataFrameオブジェクト(Seriesオブジェクト)でサクッとデータの可視化を行うためのものだと考えておきましょう(pandasの頭からMatplotlibの頭に切り替えるのってなかなか大変だと思いませんか?)。
先ほども述べましたが、これらのメソッドとMatplotlibが提供する関数は1対1に対応しているわけではありません(DataFrame.plot.kdeメソッドのようにMatplotlib側にないものありますし、pyplot.violineplot関数のようにpandasの側にないものもあります)。とはいえ、多くの場合、相互に対応するメソッドと関数は似た振る舞いをします。さらに、プラスアルファの振る舞いをDataFrameオブジェクト側のメソッドが提供することもあります。
以下に例を示します。
Size = 300
np.random.seed(42)
groupA = np.random.choice(['A', 'B', 'C'], size=size)
groupB = np.random.choice(['foo', 'bar'], size=size)
values = np.random.normal(loc=5.0, scale=2.0, size=size)
df = pd.DataFrame({'groupA': groupA, 'groupB': groupB, 'values': values})
df.head(10)
これは2種類のグループ(groupAとgroupB)と何らかのデータ(values)で構成されるDataFrameオブジェクトです。

この'values'列の箱ひげ図を描画してみましょう。ここではMatplotlibを使っています。
plt.boxplot(df['values'])
plt.show()
結果はこの通り、箱ひげ図が1つ表示されました。
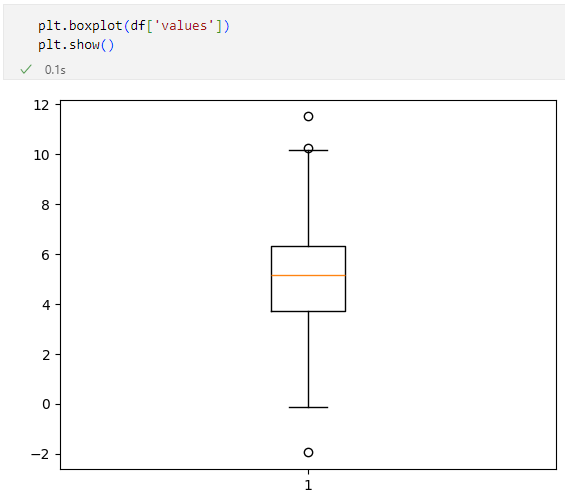 箱ひげ図は1つだけ描画される
箱ひげ図は1つだけ描画されるこれは全体の様子を見るにはよいかもしれません。しかし、groupAの値で分布がどう異なるかを見たい、あるいはgroupBの値で分布がどうなるかを見たいといったときにはどうすればよいでしょう。あるいはgroupA×groupBだったら?
Matplotlibを使うとしたら、次のようなコードを書くことになるでしょう。
g = [group['values'] for _, group in df.groupby('groupA')]
plt.boxplot(g, tick_labels=['A', 'B', 'C'])
plt.show()
ここではDataFrameオブジェクトのgroupbyメソッドを使って、'groupA'列の値を使ってグループ化し、それぞれのグループごとに’values’列の値を得て、それをリスト(g)の要素としています。これはpyplot.boxplot関数に渡すことで、グループごとの箱ひげ図を描画しているわけです。
こうすれば、グループごとに値がどのような分布になっているかを可視化できます。
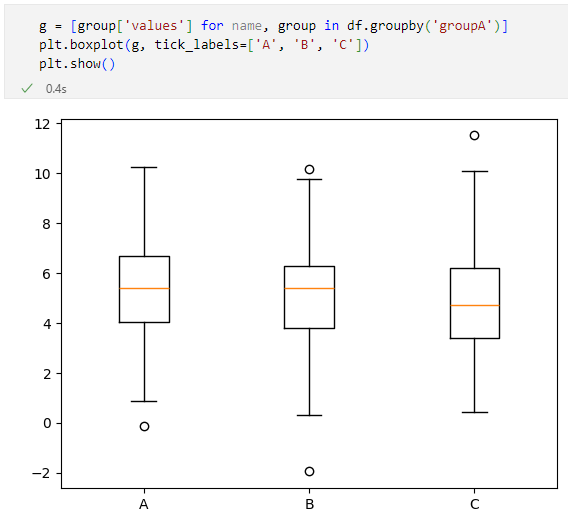 'groupA'列の値でグループ化された'value'列の箱ひげ図
'groupA'列の値でグループ化された'value'列の箱ひげ図事前に自分でグループ化しなければならないのは少し面倒です。こんなときに役立つのがDataFrame.plot.boxメソッド(あるいはkind='box'を指定したDataFrame.plot呼び出しです)。以下に例を示します。
df.plot.box(by='groupA', color='black', medianprops={'color': 'red'})
plt.show()
byパラメーターにグループ化したい列を指定するだけで、次のような結果が得られます(上の結果と同じ見た目にするためにcolorパラメーターとmedianpropsパラメーターを指定しています)。
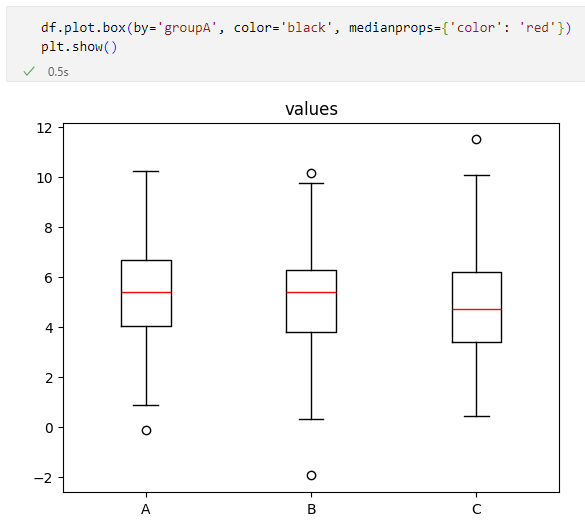 byパラメーターの指定により簡単にグループ化できた
byパラメーターの指定により簡単にグループ化できた'groupA'列と'groupB'列でグループ化して箱ひげ図を描くこともカンタンです。以下のようにグループ化したい列をリストの要素とするだけです。
df.plot(kind='box', by=['groupA', 'groupB'])
plt.show()
すると、結果は次のようになります。
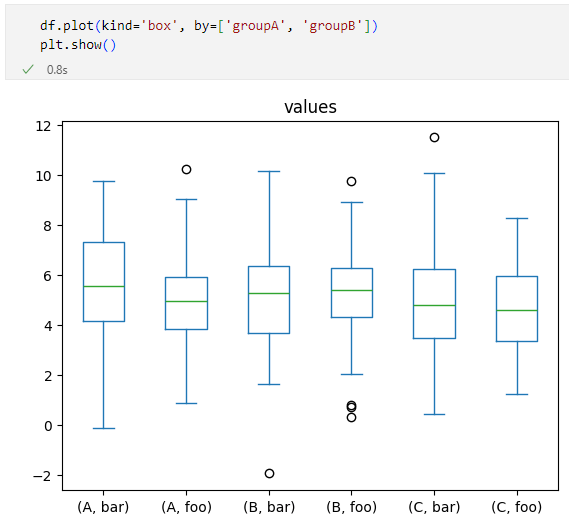 3×2=6つにグループ化された箱ひげ図
3×2=6つにグループ化された箱ひげ図ちなみに'value'列のような列が複数あったしたらどうでしょう。
size = 300
np.random.seed(42)
df = pd.DataFrame({
'groupA': np.random.choice(['A', 'B', 'C'], size=size),
'groupB': np.random.choice(['foo', 'bar'], size=size),
'values0': np.random.normal(loc=5.0, scale=2.0, size=size),
'values1': np.random.normal(loc=6.0, scale=2.0, size=size)
})
df.plot.box(by='groupA')
plt.show()
この場合は、以下のように2つの列のそれぞれについてグループ化した結果を可視化してくれます。
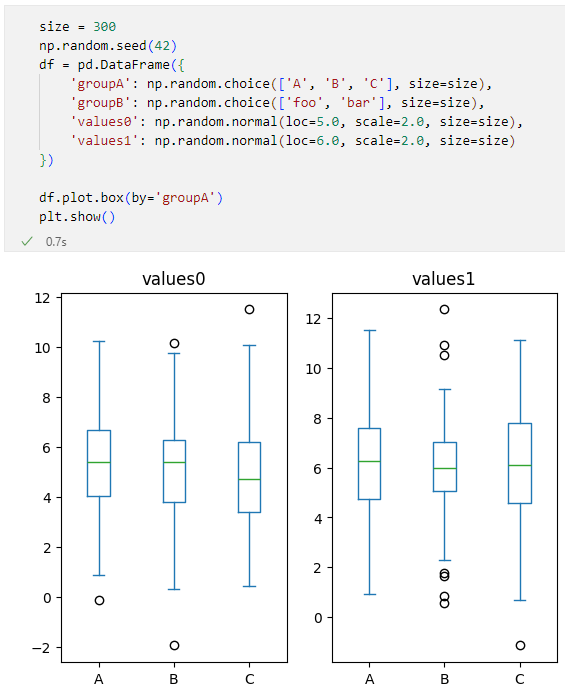 列ごとにグループ化と可視化を行ってくれる
列ごとにグループ化と可視化を行ってくれるどちらかの列だけが必要であれば、columnパラメーターに列を指定することも可能です(ここでは結果は示しません)。
Matplotlibが提供するboxplot関数では事前に自分でグループ化をしなければならなかったのが、DataFrame.plot.boxメソッドならbyパラメーターにグループ化したい列を指定するだけというのがカンタンでよいですね。グループ化して可視化したいのであれば、こちらを使うことをオススメします。
DataFrameオブジェクトが持つboxplot/histメソッドを使う
「オススメします」と書いたのですが、実は同様ことをしてくれるメソッドがDataFrameオブジェクトにはもう1つあります。それがDataFrame.boxplotメソッドです。DataFrame.plot.boxメソッドと同様に使えます。以下に例を示します。
ize = 300
np.random.seed(42)
df = pd.DataFrame({
'groupA': np.random.choice(['A', 'B', 'C'], size=size),
'groupB': np.random.choice(['foo', 'bar'], size=size),
'values0': np.random.normal(loc=5.0, scale=2.0, size=size),
'values1': np.random.normal(loc=6.0, scale=2.0, size=size)
})
df.boxplot(by='groupA', column='values0')
plt.show()
先ほどと比べると、DataFrame.plot.boxメソッド呼び出しがDataFrame.boxplotメソッド呼び出しに変わっただけです(columnパラメーターを指定したので、'value0'列の箱ひげ図だけが表示されるようになります)。
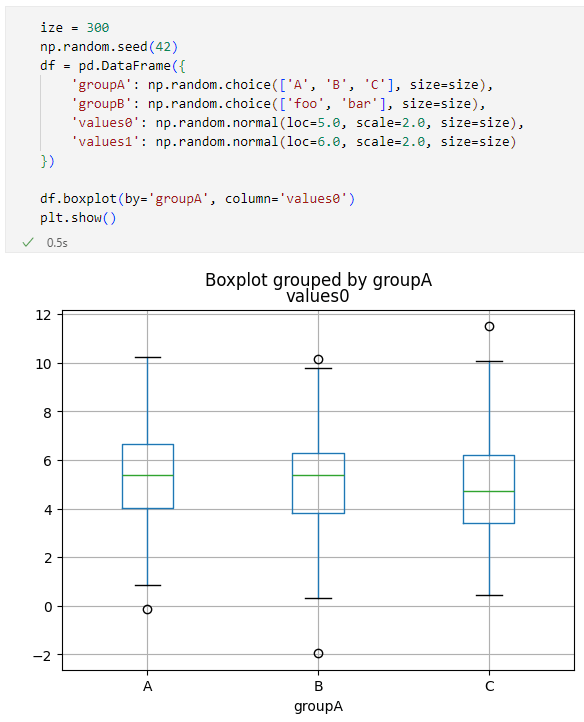 DataFrame.boxplotメソッドを呼び出した結果
DataFrame.boxplotメソッドを呼び出した結果なぜ似たことをするメソッドが複数あるのかについての説明は筆者にはできません。明確に違うのは、DataFrame.boxplotメソッドでは何も指定しないとグリッドが表示されるところです。もう1つ、Series.plot.boxメソッドはあっても、Series.boxplotメソッドがない点も違っています。
s = pd.Series(np.random.normal(size=100))
s.plot.box()
plt.show()
s.boxplot() # AttributeError
普段からDataFrame.plot属性を使っているのであれば、そちらを使えばよいでしょうし、DataFrame.boxplotメソッドを使い慣れているというのであれば、そちらを使えばよいでしょう。この辺はお好みしだいだと思います。
そして、DataFrame.boxplotメソッドと同様にDataFrameオブジェクトの直接のメソッドとしてポツンと存在しているものがもう1つあります。それがDataFrame.histメソッドです。
以下にDataFrame.plot.histメソッドの使用例を示します。
np.random.seed(13)
loc = 50
scale = 19
size = 100
df = pd.DataFrame({
'v0': np.random.normal(loc=loc-10, scale=scale+1, size=size),
'v1': np.random.normal(loc=loc, scale=scale, size=size)
})
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
df.plot.hist(bins=bins, edgecolor='black', alpha=0.3)
plt.show()
実行すると、次のようになります。
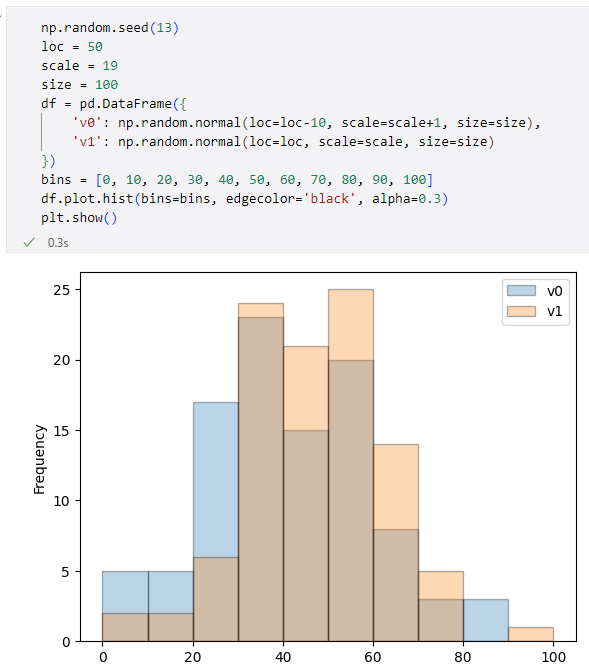 2つのヒストグラムが重ねて表示される
2つのヒストグラムが重ねて表示される一方、DataFrame.histメソッドを使うコードの例は次のようになります。
np.random.seed(13)
loc = 50
scale = 19
size = 100
df = pd.DataFrame({
'v0': np.random.normal(loc=loc-10, scale=scale+1, size=size),
'v1': np.random.normal(loc=loc, scale=scale, size=size)
})
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
df.hist(bins=bins, edgecolor='black', alpha=0.3)
plt.show()
こちらを実行すると次のようになりました。
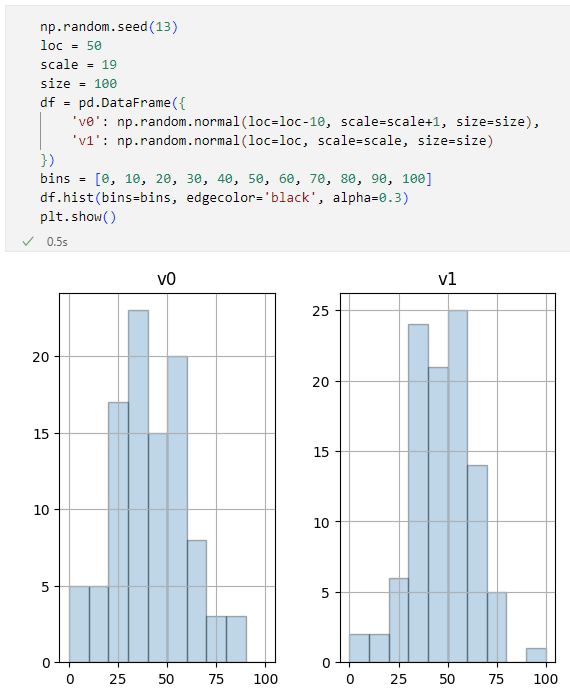 サブプロットに別々のグラフとして描画される
サブプロットに別々のグラフとして描画されるDataFrame.histメソッドではそれぞれのヒストグラムが別々のサブプロット(描画領域)に表示されました。なるほど。これは明確に振る舞いが異なっていますね。ちょびっと可視化したいというときに、どんなコードを書けば良かったかに悩むのであれば、好みの表示の方を覚えておいて、普段はそれを使うように習慣づけておくのがよいかもしれません。
なお、boxplotメソッドはDataFrameオブジェクトにしかありませんでしたが、histメソッドはSeriesオブジェクトにもあることも余談としてお伝えしておきましょう。
今回で終わるつもりだったのですが、なぜだか箱ひげ図の話題が増えてしまったことで、次回にもう少しだけ積み残しがあると思います。しばしお待ちを。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。