[Matplotlib超入門:pyplot編]折れ線グラフ/散布図/棒グラフ/ヒストグラム/円グラフを作成してみよう:Pythonデータ処理入門
Pythonでデータを可視化するために広く使われているMatplotlib。そのpyplotインタフェースを使って、さまざまなグラggフを手軽に作成する方法を紹介します。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
なお、【Matplotlib超入門:pyplot編】では以下のバージョンを使用しています。
- Python 3.13
- Matplotlib 3.10.3
Matplotlibとは
Matplotlibはデータの可視化を行うためにPythonで広く使われているライブラリです。大量の数値データを扱うNumPyやデータ解析に使用するpandasなどのライブラリは便利ですが、それらが扱うデータをビジュアルに表現するためのツールがMatplotlibです(pandasのDataFrameオブジェクトにはplotメソッドがありますが、これは内部的にはMatplotlibを使ってデータをプロットします)。
サイン曲線や棒グラフのような一般的なグラフだけではなく、各種データの相関を表すヒートマップや、データが分布する範囲を可視化する箱ひげ図など、さまざまな種類のデータをさまざまな形で表現できるのがMatplotlibの大きな特徴といえるでしょう。

Matplotlibはもともと、MathWorks提供の「MATLAB」という有償の数値解析ソフトウェアが持つプロット機能と似たものをPythonでも実現することを目的として開発されました。Matplotlibの「pyplotインタフェース」はまさにこのMATLABと似た使い勝手のプロット機能を提供するものです。今回からは3回に分けてこのpyplotインタフェースの基本的な使い方を紹介していきます。
pyplotインタフェースとオブジェクト指向インタフェース
pyplotインタフェースという言葉が出てきましたが、Matplotlibにはもう一つのインタフェースがあります。それが「オブジェクト指向インタフェース」または「Axesインタフェース」と呼ばれるインタフェースです。
両者の違いを簡単にまとめておきましょう。
- pyplotインタフェース:MATLAB同様の使い勝手を提供する。グラフ描画の対象は「暗黙的」に決定される(どこに何を描画するのかをpyplotが管理してくれる)。ちょっとしたグラフを対話的に描画するのにオススメ。ただし、複数のグラフをプログラム的に取り扱ったり、グラフを関数にまとめて再利用したりしようとするのであれば、以下のオブジェクト指向インタフェースの方が扱いやすい。実際にはpyplotインタフェースはオブジェクト指向インタフェースを簡便に使うためのラッパー的な存在といえる
- オブジェクト指向インタフェース:Figureオブジェクト、Axesオブジェクト、Artistオブジェクトなど、Matplotlibが提供するさまざまなオブジェクトを使ってグラフを描画するためのインタフェース。コードを書く側がどこに何を描くかを「明示的」に指定する必要がある。プログラム的にグラフ描画を処理するのに向いている
これ以上踏み込むことは、ここではやめにしておいて、今回はpyplotインタフェースを使って幾つかの種類のグラフを描画してみることにします。ただし、その前にMatplotlibをインストールして、Pythonコードから使えるように準備する必要があります。
Matplotlibのインストールとインポート
MatplotlibはPythonに標準で付属するライブラリではありません。そのため、pipコマンドなどを使って、事前にインストールしておく必要があります。ここではpipコマンドを使いますが、その他の方法についてはMatplotlibのドキュメント「Installation」を参照してください。
インストールといっても難しいことはなく、「pip install matplotlib」コマンドを実行するだけです。本連載では、pyplot_notebooksディレクトリを作成して、そこにPythonのvenvモジュールを使って仮想環境を構築して、そこにMatplotlibやNumPy、pandasなどをインストールした上で、pyplot_01.ipynbなどのノートブックを作成していくことにします(「pyplot_01.ipynb」ファイルは第1回で使用するノートブックです)。
なお、実行環境はVisual Studio Codeとします。また、筆者の環境はWindowsとmacOSの両者なのでWindows用の仮想環境は「venv_win」に、macOS用の仮想環境は「venv_mac」に作成するものとします。
Visual Studio Code(以下、VS Code)で「pip install matplotlib numpy pandas」コマンドを実行し、MatplotlibとNumPy、pandasを仮想環境へインストールしているところを以下に示します(実際には、これらが依存しているモジュールや、Visual Studio Codeでノートブックを実行するのに必要なモジュールもインストールしています)。

インストールができたら、後はMatplotlibを使用する環境でこれをインポートするだけです。以下はVS Codeでノートブックを新規に作成し、そこで今インストールしたMatplotlib、NumPy、pandasをインポートしているところです。注意するのはMatplotlibのpyplotモジュールを「plt」としてインポートしているところです。これはMatplotlibを使用する際の慣用的なインポートの仕方なので覚えておきましょう。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
VS Codeで上のコードを実行したところを以下に示します。

なお、VS Codeでノートブックを作成し、そこからコードを実行しようとすると「ipykernelモジュールのインストールが必要だ」というダイアログが表示されるかもしれません。その場合は、指示に従ってipykernelモジュールをインストールしてください。
pyplotで基本のグラフを描くには
準備ができたところで、幾つかのグラフを実際に描画しながら、pyplotインタフェースの簡単な使い方を見ていきましょう。ここでは以下のグラフを描いてみます。
これらのグラフを描きながら、描画したグラフを表示する方法、X軸/Y軸のラベルの指定、グラフのタイトルの指定、凡例の表示、グリッドの表示などについても簡単に紹介します。
折れ線グラフを作成するには:pyplot.plot関数
まずは折れ線グラフを描いてみます。折れ線グラフとは、(x0, y0)、(x1, y1)、……で指定されるグラフ上の点を線で結んでいくグラフのことです。pyplotインタフェースで折れ線グラフを描画するにはmatplotlib.pyplot.plot関数を使います(以下ではmatplotlibを省略して、pyplot.plot関数のような表記をすることにしましょう。また、サンプルコード中では「pyplot」ではなく「plt」となる点には注意してください)。
pyplot.plot関数の代表的な使い方を以下にまとめます。パラメーターの説明にある配列はPythonのリスト、NumPyのndarray、pandasのSeriesやDataFrameなどが該当します(以下、同様)。
pyplot.plot関数
pyplot.plot([x], y, [fmt], [data])
X軸の値を含む配列とY軸の値を含む配列を与えることで、(x[0], y[0])、(x[1], y[1])、……などの座標を結ぶ直線を描画する。
パラメーターは以下の通り。
- [x]:X軸の値を含む配列またはdataパラメーターを指定した場合にはdataパラメーターの列ラベル。省略可能。省略した場合はrange(len(y))を指定したものとして解釈される。つまり、0、1、……がY軸の値を含む配列の長さ(−1)まで続く
- y:Y軸の値を含む配列またはdataパラメーターを指定した場合にはdataパラメーターの列ラベル。この場合、xとyに指定した列ラベルの値を用いてグラフが描画される
- [fmt]:グラフの線色、マーカーの種類などを指定する文字列。省略可能。省略した場合はMatplotlibのデフォルトの設定が使用される
- [data]:描画に使用するオブジェクトを指定する。省略可能。省略した場合はxとyには配列を指定すること
これだけ読むと少し難しく感じるかもしれません。が、幾つかの例を見ながら、実際の動作を確認してみましょう。最初は簡単に「y = 2 * x」という直線を考えてみます。
x = [0, 1, 2, 3, 4]
y = [n * 2 for n in x]
plt.plot(x, y)
plt.show()
変数xには[0, 1, 2, 3, 4]というPythonのリストが代入されています。変数yにはリスト内包表記を使って、変数xの値を2倍した値を要素とするリストが代入されています。これらをpyplot.plot関数に渡して、最後にpyplot.show関数を呼び出すことで、グラフがプロットされます。実行結果は次の通り。
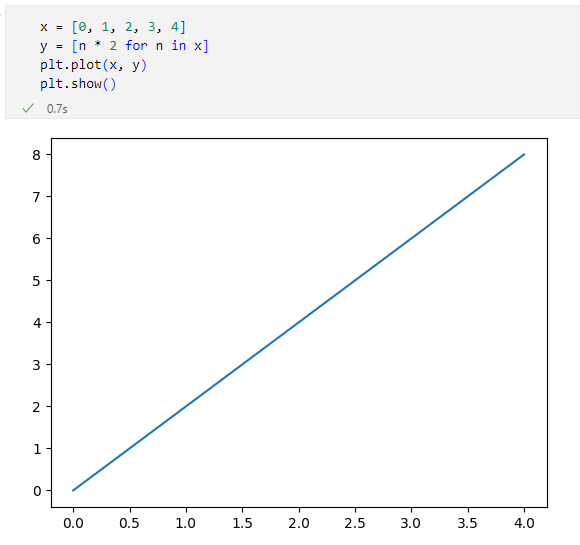 「y = 2 * x」というグラフをプロットしたところ
「y = 2 * x」というグラフをプロットしたところX軸の値は0.0〜4.0に、Y軸の値は0.0〜8.0になっていて、(0.0, 0.0)から(4.0, 8.0)まで直線が引かれました。思った通りの結果になっていますね。これがpyplot.plot関数の基本的な使い方といえます。
X軸の値を含む配列は省略可能なので、上のコードは次のようにしても同じ結果になります。
x = [0, 1, 2, 3, 4]
y = [n * 2 for n in x]
plt.plot(y)
plt.show()
X軸の値を含むリストが0始まりで間隔が1の等差数列になっているから省略できている点には注意してください。それ以外の配列の場合には指定が必須です。
また、Y軸の値は2次元以上の配列を要素とする配列にすることも可能です。言葉で説明するのが大変なのでコードで例を示します。
x = [0, 1, 2, 3, 4]
y = [(n * 2, n + 1) for n in x]
plt.plot(x, y)
plt.show()
変数yにはX軸の値を2倍したものとX軸の値に1を足したもの、これら2つの要素からなるタプルを含むリストが代入されています。つまり、[(0, 1), (2, 2), (4, 3), (6, 4), (8, 5)]というリストが変数yの値です。これをpyplot.plot関数に渡すと「y = 2 * x」と「y = x + 1」のグラフがプロットされます。グラフの線色が自動的に変わっている点にも注目してください。
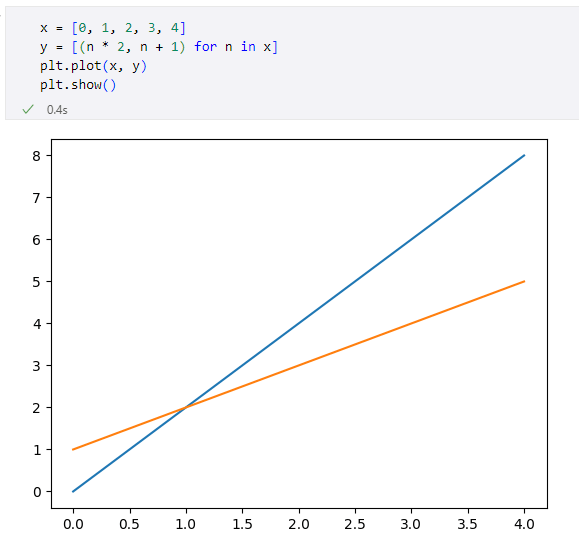 「y = 2 * x」と「y = x + 1」のグラフがプロットされた
「y = 2 * x」と「y = x + 1」のグラフがプロットされたこれと同じグラフは、pyplot.plot関数を2回使っても描画できます(実行結果は省略)。
x = [0, 1, 2, 3, 4]
y0 = [n * 2 for n in x]
y1 = [n + 1 for n in x]
plt.plot(x, y0)
plt.plot(x, y1)
plt.show()
どちらがよいかは、そのときどきの判断によるでしょう。後者の方法の方が直感的のように筆者には感じられますが、前者のやり方が気に入るという方もいるはずです。
次にdataパラメーターにプロット対象のデータを指定して、その列ラベルをxパラメーターとyパラメーターに指定する例を紹介します。
x = [0, 1, 2, 3, 4]
y = [n * 2 for n in x]
df = pd.DataFrame({'x': x, 'y': y})
plt.plot('x', 'y', '', data=df)
plt.show()
この例では、変数xと変数yの値を使ってpandasのDataFrameオブジェクトを作成しています。このときに、変数xの値を含む列のラベルは'x'に、変数yの値を含む列のラベルは'y'に指定している点に着目してください。そして、pyplot.plot関数では「data=df」と指定し、2つのパラメーターxとyには上で指定した列ラベルを文字列として指定しています。実行結果は省略します。
ところで、上のコードでは第3引数(書式の例で指定したfmtパラメーター)に空文字列「''」を指定しています。これはなぜでしょう。ここで先ほどのpyplot.plot関数の書式を再掲します。
pyplot.plot([x], y, [fmt], [data])
先頭の[x]が省略可能なことに着目してください。実は上のコード例から空文字列の指定を省略して、「plt.plot('x', 'y', data=df)」とした場合、これは2種類の解釈が成り立ってしまうのです。1つはxパラメーターの指定を省略し、yパラメーターに文字列'x'を、fmtパラメーターに文字列'y'を指定したものとする解釈。もう1つはxパラメーターに文字列'x'を、yパラメーターに文字列'y'を指定(して、fmtパラメーターの指定を省略)したものとする解釈です。どちらの解釈も成り立ってしまうので、Matplotlibは警告を発生します。これを避けるため、ここではfmtパラメーターに空文字列''を指定したのです。
では、fmtパラメーターとは何でしょう。書式の紹介でも述べましたが、これはグラフの線色やマーカーを指定する文字列です。'y'というのは線色を黄色(yellow)にすることを意味します(そのため、上では'y'がfmtパラメーターの指定ではないことが明確になるように空文字列を指定しました)。この他にもマーカーの種類、線種(実線、点線など)を指定可能です。
具体的には以下のような文字列を組み合わせて指定します(一部抜粋。全ての種類についてはMatplotlibのドキュメント「matplotlib.pyplot.plot」を参照)。
- 線種:実線('-')、破線('--')、一点鎖線('-.')、点線(':')
- 線色: 赤('r')、青('b')、黄('y')、緑('g')など
- マーカー:●('o')、ポイント('.')、ピクセル(',')、下向き三角('v')、上向き三角('^')、左向き三角('<')、右向き三角('>')など
簡単な例を1つ示します。
x = np.array([0, 1, 2, 3, 4])
y = 2 * x
plt.plot(x, y, 'go:') # 線色:緑、○、点線
plt.show()
fmtパラメーターには'go:'を指定しています。'g'は緑の線色を、'o'はマーカーに●を、':'は点線を意味することに注目してください。実際にそうしたグラフがプロットされるでしょうか。以下がその結果です。
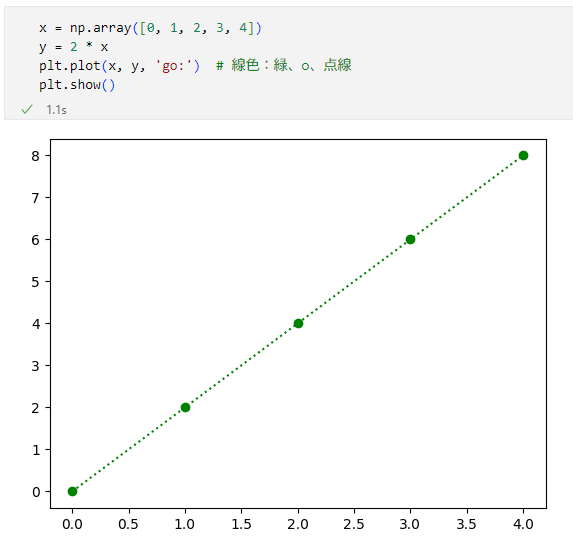 マーカー:●、線色:緑、線種:点線のグラフがプロットされた
マーカー:●、線色:緑、線種:点線のグラフがプロットされたどうやらそのようなグラフになっているようです。このようにfmtパラメーターを使うと、簡便にグラフのカスタマイズが行えます。fmtパラメーターに加えて、例えば線の太さ(linewidthパラメーター)、マーカーのサイズ(markersizeパラメーター)なども指定できるので、Matplotlibで描画するグラフは非常に表現力が豊かだといえます。
ずいぶんと長くなってしまいました。次に、散布図について見てみましょう。
散布図を作成するには:pyplot.scatter関数
散布図はグラフの縦軸と横軸に割り当てた2つの項目を使って、データがどのように分布しているかを可視化するために使用します。pyplotインタフェースでは、pyplot.scatter関数で散布図をプロットします。
pyplot.scatter関数
pyplot.scatter(x, y, s=None, c=None, *, marker=None)
X軸とY軸の値を含む配列を与えると、その散布図をプロットする。
パラメーターは次の通り。
- x/y:データの位置を示す
- s:マーカーのサイズ
- c:マーカーの色
- marker:マーカーのスタイル
以下に例を示します。
center0 = 8.5
center1 = 6.5
std_dev = 1.0
num = 100
np.random.seed(2)
x0 = np.random.normal(loc=center0, scale=std_dev, size=num)
y0 = np.random.normal(loc=center0, scale=std_dev, size=num)
x1 = np.random.normal(loc=center1, scale=std_dev, size=num)
y1 = np.random.normal(loc=center1, scale=std_dev, size=num)
plt.scatter(x0, y0)
plt.scatter(x1, y1)
plt.show()
ここでは、(8.5, 8.5)を中心に標準偏差1で分布するようなデータと、(6.5, 6.5)を中心に標準偏差1で分布するようなデータの2種類のデータを作成し、それらを変数x0/y0および変数x1/y1に代入しています(このとき、numpy.random.seed関数で乱数のシードを指定することで、常に一定の乱数を得られるようにしています)。そして、それらをpyplot.scatter関数に渡して、散布図をプロットしています。
2種類のデータは分布の中心が異なるので、散布図をプロットすると、その分布の仕方が異なるはずです。これを確認してみましょう。

そんな感じの散布図がプロットできました。sパラメーター(マーカーのサイズ)、cパラメーター(マーカーの色)、markerパラメーター(マーカーの種類)を指定する例を以下に示します。
plt.scatter(x0, y0, s=20, c='b')
plt.scatter(x1, y1, s=30, c='red', marker='^')
plt.show()
ここでは最初のデータのマーカーサイズを20に、マーカーの色を青('b')に指定しています。次のデータについてはマーカーサイズを30に、マーカーの色を赤('red')に、マーカーの種類を上向き三角('^')に指定しています。これにより、プロットされる散布図は次のようになります。
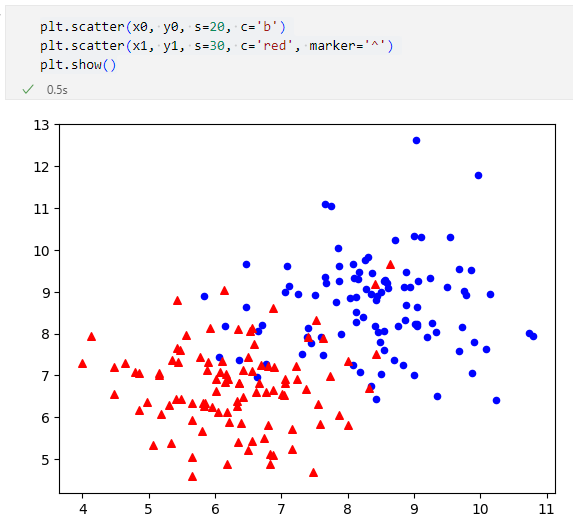 マーカーの指定を行った散布図
マーカーの指定を行った散布図ここでこれまでにはやっていないグラフの装飾についても見てみましょう。
- X軸/Y軸のラベル:pyplot.xlabel関数/pyplot.ylabel関数
- グラフのタイトル:pyplot.title関数
- 凡例:pyplot.legend関数
pyplot.xlabel関数/pyplot.ylabel関数/pyplot.title関数には文字列としてラベルあるいはタイトルを指定します。pyplot.legend関数はそれぞれの系列を表す文字列を要素とするリストを指定します。なお、pyplot.xlabel関数とpyplot.title関数ではlocパラメーターに'center'/'left'/'right'のいずれかを、pyplot.ylabel関数ではlocパラメーターに'center'/'top'/'bottom'のいずれかを指定することでラベルやタイトルの表示位置を指定可能です(デフォルトは'center')。pyplot.legend関数では'upper left'/'upper center'/'upper right'/'center left'/'center'/'center right'/'lower left'/'lower center'/'lower right'などを用いて凡例の表示位置を指定できます。なお、標準の状態では日本語は使用できないので、注意してください。
以下に例を示します。
plt.scatter(x0, y0, s=20, c='b')
plt.scatter(x1, y1, s=30, c='red', marker='^')
plt.xlabel('X-axis', loc='right')
plt.ylabel('Y-axis', loc='top')
plt.title('Scatter Plot', loc='left')
plt.legend(['Group 1', 'Group 2'], loc='upper right')
plt.show()
ここではX軸のラベルは'X-axis'で表示位置は'right'、Y軸のラベルは'Y-axis'で表示位置は'top'、グラフのタイトルは'Scatter Plot'で表示位置は左、凡例では最初の系列が'Group 1'で次の系列が'Group 2'として、表示位置は'upper right'にしています。指定した通りにラベルやタイトル、凡例が表示されていることを確認してください。

散布図のプロットの基本は以上です。次に棒グラフをプロットしてみます。
棒グラフを作成するには:pyplot.bar関数
棒グラフは、特定のカテゴリごとにそれぞれのボリュームがどのくらいあるかを比較するのに使用します。例えば、何かの販売金額を年度別に比較するとか、地域ごとの人口を比較するといった場合がそうです。棒グラフはpyplot.bar関数を使ってプロットできます。
以下に書式を示します(一部抜粋)。
pyplot.bar関数
pyplot.bar(x, height, width=0.8, bottom=None, *, align='center', data=None)
xに指定した値に対応するheightを棒グラフとしてプロットする。
パラメーターは次の通り。
- x:X軸の値。数値ではなく、文字列も指定可能(カテゴリカルデータ)
- height:バーの高さ
- width:バーの横幅。省略時は0.8が指定されたものとして扱われる
- bottom:バー最下部のY軸の値
- align:バーの表示領域における幅寄せの指定。中央('center')か左寄せ('edge')を指定可能
簡単な例を以下に示します。
x = np.array([0, 1, 2, 3, 4])
np.random.seed(12)
y = np.random.uniform(low=10.0, high=50, size=5)
plt.bar(x, y)
plt.show()
X軸の値は整数値、Y軸(height)の値は一様分布(最小値10、最大値50)の乱数を使って生成しています。これらをpyplot.bar関数に渡すと、次のようなグラフがプロットされます。
 棒グラフの表示
棒グラフの表示棒グラフがきちんと表示されました(グラフを見て、特に思うことはないのでアッサリです)。bottomパラメーター/widthパラメーター/alignパラメーターを指定する例も紹介しましょう。
x = np.array([0, 1, 2, 3, 4])
np.random.seed(12)
y = np.random.uniform(low=10.0, high=50, size=5)
plt.bar(x, y, bottom=5, width=0.7, align='edge')
plt.show()
ここではbottomパラメーターに5を、widthパラメーターに0.6を、alignパラメーターに'edge'を指定しました。これでグラフがどう変化するかを確認してください。
 各バーがY=5からプロットされるようになって、グラフが細くなり、X軸の値にグラフの左端が接するようになった
各バーがY=5からプロットされるようになって、グラフが細くなり、X軸の値にグラフの左端が接するようになった各バーがY=5からプロットされるようになって、グラフが細くなり、X軸の値にグラフの左端が接するようになったことが分かります。
上には示しませんでしたが、これらのパラメーター以外にもバーの色を個別に指定したり(colorパラメーター)、境界線の色を変更したり(edgecolorパラメーター)できます。それらについても例を示します。
x = np.array([0, 1, 2, 3, 4])
np.random.seed(12)
y = np.random.uniform(low=10.0, high=50, size=5)
colors = ['r', 'g', 'b', 'y']
plt.bar(x, y, color=colors, edgecolor='k')
plt.show()
変数colorsには['r', 'g', 'b', 'y']というリストを代入し、これをcolorパラメーターに指定しています。また、edgecolorパラメーターには'k'を指定しています。'k'は黒(black)を意味している点には注意してください('b'は青の指定)。実行結果を以下に示します。
 バーの色と境界線の色が変更された
バーの色と境界線の色が変更されたcolorsには色を4つしか指定していませんでしたが、5つ目のバーでは色が循環して赤が再度使われている点に注目してください。また、境界線も指定通りに黒になりました。境界線をクッキリさせたいのであれば、edgecolorの指定は必須です。
詳細な説明は省略しますが、以下のように積み上げ棒グラフをプロットすることも可能です。
np.random.seed(5)
x = ['A', 'B', 'C']
y = {
'stack0': np.random.uniform(low=5, high=20, size=3),
'stack1': np.random.uniform(low=5, high=20, size=3)
}
bottom = np.zeros(3)
for k, v in y.items():
p = plt.bar(x, v, bottom=bottom, label=k)
bottom += v
plt.bar_label(p, label_type='center', color='w')
plt.legend()
plt.title('Stacked Bar Chart')
plt.show()
Y軸の値として辞書を使用して、そのキーと値を反復しながら、bottomパラメーターの値を積み上がったグラフの上端(次に積むバーの下端)となるように調整することで積み上げ棒グラフをプロットしています。また、pyplot.bar_label関数によるバーにそれぞれの値も表示するようにしています。
実行結果は次のようになります。
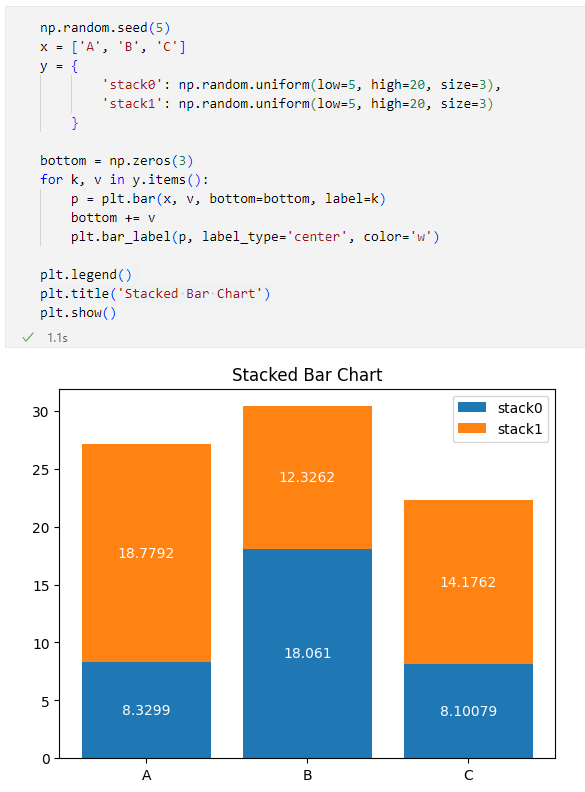 積み上げ棒グラフ
積み上げ棒グラフ次にヒストグラムのプロットを見ていきましょう。
ヒストグラムを作成するには:pyplot.hist関数
棒グラフはX軸の値が離散的な場合に、それぞれのボリュームを比較するのに使用しますが、X軸の値が連続的な場合にそれらを一定の間隔に区切ってボリュームを比較するために使用するのがヒストグラムです。例えば、0歳から99歳までを10歳ごとに区切り人数を比較する場合や、身長を10センチごとに区切ってそこに入る人数を比較するといった場合に使用できます。ヒストグラムはpyplot.hist関数でプロットします。
以下に書式を示します(一部抜粋)。
pyplot.hist関数
pyplot.hist(x, bins=None)
xに与えたデータをbinsに指定した数のビンに分類し、それぞれのビンにどれだけのデータが含まれるかをプロットする。
パラメーターは以下の通り(一部)。
- x:入力データ
- bins:作成するビンの数を整数値として、またはビンの境界値をシーケンス(リストなど)として指定。省略時は10が指定されたものとして扱われる
簡単な例を以下に示します。
np.random.seed(13)
loc = 50
scale = 19
size = 100
x = np.random.normal(loc=loc, scale=scale, size=size)
plt.hist(x, bins=10)
plt.show()
ここでは50を中心に標準偏差19で正規分布するデータを作成しています(データ数は100個)。これをpyplot.hist関数に与えた結果が以下の画像です(ビンの数はデフォルト値と同じ10個)。

筆者が思っていたのと少し違うグラフになりました。といっても、全体的な形の話ではなく、グラフが0〜100の範囲を10等分したビンに入ることを予想していたのにそうはなっていそうもないからです。
これは次のコードを実行すると分かります。
print(x.min(), x.max()) # 8.444809808300668 90.85727638024113
ビンの数を指定した場合、この最小値と最大値の間を指定した数のビンに分割するようです。「そうじゃなくって……」というときには、「こんな感じのビンでよろしく!」とビンを明示的に指定するのがよいでしょう。例を次に示します。
np.random.seed(13)
loc = 50
scale = 19
size = 100
x = np.random.normal(loc=loc, scale=scale, size=size)
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
plt.hist(x, bins=bins, edgecolor='black')
plt.show()
この場合、最初のビンは[0, 10)という半開区間になります(境界値の10はこのビンには含まれません)。以降のビンは[10, 20)、[20, 30)、[30, 40)、……のように半開区間が続き、最後のビンだけ[90, 100]と境界値の100を含むビンとなります。これをbinsパラメーターに指定して、ヒストグラムを作成しています(edgecolorパラメーターも指定しています)。
この実行結果は次のようになりました。
 0〜100の区間を10個のビンに区切ってヒストグラムを作成した結果
0〜100の区間を10個のビンに区切ってヒストグラムを作成した結果境界線も黒で引き締まって、ビンもきっちりとしました(ちゃっかり、全体の形状もかなりの正規分布な気がします)。
円グラフを作成するには:pyplot.pie関数
円グラフは、データを構成する要素の比率を可視化するために使います。ある製品群の市場シェアなど、全体に対して、特定の構成要素がどのくらいの割合を占めているかをビジュアルに表現するためのものです。pyplotインタフェースでは、円グラフはpyplot.pie関数を使ってプロットします。
以下にその書式を示します(一部抜粋)。
pyplot.pie関数
pyplot.pie(x, *, labels=None, autopct=None, startangle=0, counterclock=True)
xの円グラフをプロットする。円グラフを構成する扇形の部分(セクター、スライス、ウェッジなどと呼びます)はx/sum(x)で得られる。
パラメーターは以下の通り。
- x:データを構成する各カテゴリの値
- labels:各セクターに表示する文字列
- autopct:各セクターに自動的にパーセントを表示する際に使用するフォーマット文字列
- startangle:円グラフをどこから描き始めるかの指定。省略時はX軸(正の範囲)をスタートとして、counterclockパラメーターの値に応じて反時計回り(デフォルト)もしくは時計回りにセクターをプロットしていく
- counterclock:反時計回りに円グラフのセクターを描画するかどうかの指定
簡単な例を以下に示します。
np.random.seed(42)
x = np.random.uniform(low=5, high=30, size=5)
labels = ['A', 'B', 'C', 'D', 'E']
plt.pie(x, labels=labels)
plt.show()
ここでは一様分布なデータを用意しました(データの数は5個)。ラベルは'A'、'B'、'C'、'D'、'E'の5つです。これらをpyplot.pie関数に与えた結果が以下の画像です。
 作成された棒グラフ。円の中心部から右に伸びた直線から'A'、'B'、……という順番で各セクターが描画されている
作成された棒グラフ。円の中心部から右に伸びた直線から'A'、'B'、……という順番で各セクターが描画されている円の中心部を座標(0, 0)とすると、X軸の正数側に伸びた直線から反時計回りに'A'、'B'、……というように各セクターがプロットされているのが分かります。また、ラベルは各セクターの外側に表示されています。
では、startangleパラメーターに90を指定して開始位置をY軸(正数側)にし、counterclockパラメーターにFalseを指定して時計回りに円グラフをプロットしてみましょう。
np.random.seed(42)
x = np.random.uniform(low=5, high=30, size=5)
labels = ['A', 'B', 'C', 'D', 'E']
plt.pie(x, labels=labels, startangle=90, counterclock=False)
plt.show()
実行結果を以下に示します。上で述べたような円グラフになっていますね。
 開始位置とセクターをプロットする方向が変わった円グラフ
開始位置とセクターをプロットする方向が変わった円グラフ最後にautopctパラメーターに各セクターが占めるパーセンテージを表示するためのフォーマット文字列を指定します。このフォーマット文字列はC言語におけるPythonの「'%4d' % 100」のような%演算子を用いて文字列を書式化する際に使用するものと同様です。ここでは'%2.2f%%'を指定してみましょう。整数部2桁、小数部2桁の10進浮動小数点数値になります(最後の'%%'はパーセント記号を表示するためのエスケープシーケンス)。
np.random.seed(42)
x = np.random.uniform(low=5, high=30, size=5)
labels = ['A', 'B', 'C', 'D', 'E']
plt.pie(x, labels=labels, startangle=90, counterclock=False, autopct='%2.2f%%')
plt.show()
実行すると以下のようになりました。

autopctパラメーターを使えば、円グラフで可視化された情報をパーセント表示でさらに分かりやすく表示できます。ぜひ覚えておきましょう。
作成したグラフを保存するには:pyplot.savefig関数
作成したグラフを画像として保存する方法を紹介しておきましょう。これにはpyplot.savefig関数を使います。
以下にpyplot.savefig関数の書式を示します(一部抜粋)。
pyplot.savefig関数
pyplot.savefig(fname, *, transparent=None, dpi='figure', format=None)
現在の画像をファイルに保存する。
パラメーターは以下の通り。
- fname:保存するファイルの名前。formatパラメーターが指定されなかったときには、fnameから画像の形式が推測される。formatパラメーターが指定されたときには、それを基に画像の形式が決定される。ただし、このとき、fnameに拡張子が含まれていなくても、拡張子を追加するようなことはないことには注意
- tranaparent:Trueを指定すると透過画像として保存され、Falseを指定すると非透過画像として保存される。省略時はFalseが指定されたものとして見なされる
- dpi:画像のDPIを指定する。'figure'を指定したときには、現在の画像のDPIが使われる。省略時は'figure'が指定されたものとして扱われる
- format:画像のフォーマットを指定する。'png'、'pdf'、'svg'などを指定可能
では、最後の画像を保存してみます。
plt.savefig('piechart.png')
というところで、少し長くなったので今回はここまでとします。ちょっと詰め込み過ぎた感もありますが、今回はMatplotlibが提供するpyplotインタフェースを使って、折れ線グラフ、散布図、棒グラフ、ヒストグラム、円グラフという基本的なグラフの使い方を紹介しました。
次回はグラフを見やすくするいろいろな方法を紹介する予定です。今回紹介したグラフの装飾関数についても再度見ていくことになるでしょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。