[Pythonクイズ]タプルの要素にインデックスを使わずにアクセスしたい? 意味が伝わる形に書き換えてみよう:Pythonステップアップクイズ
タプルの要素には多くの場合「[0]」「[1]」のようなインデックスを使ってアクセスしますよね。でも、それでは何を意味しているのか分かりにくいことがあります。「意味が伝わる形」にするなら、どんな方法が考えられるでしょうか?(コード全体を見直しても構いません)

【問題】
以下に示すusersは何かのユーザーのIDと名前を要素とするタプルを格納するリストである。for文ではこのリストを反復して、取り出したタプルの要素(IDと名前)にインデックスでアクセスし、それらの処理をしている(ここでは単純に表示するだけ)。だが、インデックスはそれが意味するところが分かりにくい。もっと読みやすいコードにする方法はないだろうか。なお、正解は一つではなく、usersやその中身のデータ構造を含め、コード全体を見直してもよいこととする。
isshiki = (100, 'isshiki')
kawasaki = (101, 'kawasaki')
endo = (102, 'endo')
users = [isshiki, kawasaki, endo] # 何かのユーザー
for user in users:
print(f'{user[0]}: {user[1]}') # ユーザーのIDと名前を表示
# 出力結果:
# 100: isshiki
# 101: kawasaki
# 102: endo
どの方法が一番よいかな?
冒頭の画像の彼がボヤいていますが、正解はたくさんあります。筆者が用意したのは4つですが、まだあるかもしれません。そして、今回3つの大規模言語モデル(LLM)には筆者が用意した4つの方法で一番よさげなものがどれかを尋ねてみました。その結果については最後にご紹介しますね。

どうもHPかわさきです。
「Zen of Python」には「There should be one-- and preferably only one --obvious way to do it.」って言葉がありますよね。テキトーに訳すと「何かをするのにコレだって方法が(可能であれば)1つだけあるべき」みたいになると思います。
しかしlst.append(x)はlst += [x]と書けるように、Pythonには同じ目的を実現する複数の書き方が用意されていることもあるんですよねー。今回のテーマはコード全体の設計を含めて考えてよいことにしたので、なおさら正解が幾つも出てくるわけです。そーゆー問題です。今回は。
【答え】
筆者が用意した正解は4つあります。
- for文でアンパック代入する
- 名前付きタプル(collections.namedtuple)を使う
- タプルじゃなくて辞書を使う
- データクラスを使う
ざっくりとコードだけお見せしましょう。解説はその後で。
# for文でアンパック代入する
isshiki = (100, 'isshiki')
kawasaki = (101, 'kawasaki')
endo = (102, 'endo')
users = [isshiki, kawasaki, endo] # 何かのユーザー
for user_id, user_name in users:
print(f'{user_id}: {user_name}') # ユーザーのIDと名前を表示
# 名前付きタプル(collections.namedtuple)を使う
from collections import namedtuple
User = namedtuple('User', ['id', 'name'])
isshiki = User(100, 'isshiki')
kawasaki = User(101, 'kawasaki')
endo = User(102, 'endo')
users = [isshiki, kawasaki, endo]
for user in users:
print(f'{user.id}: {user.name}')
# タプルじゃなくて辞書を使う
isshiki = {'id': 100, 'name': 'isshiki'}
kawasaki = {'id': 101, 'name': 'kawasaki'}
endo = {'id': 102, 'name': 'endo'}
users = [isshiki, kawasaki, endo]
for user in users:
print(f'{user["id"]}: {user["name"]}')
# データクラスを使う
from dataclasses import dataclass
@dataclass
class User:
id: int
name: str
isshiki = User(100, 'isshiki')
kawasaki = User(101, 'kawasaki')
endo = User(102, 'endo')
users = [isshiki, kawasaki, endo]
for user in users:
print(f'{user.id}: {user.name}')
カンタンなのはアンパック代入を使う方法です。名前付きタプルとデータクラスはともにUserという型を作成し、それらのインスタンスが持つidやnameという属性が問題文にあったタプルの各要素に対応します。辞書の場合は、タプルの要素にインデックスでアクセスしていたところをキーを使ってアクセスするようになります。

以下ではそれぞれの方法について解説をして、それらを比較してみます。
【解説】
問題文のコードは以下のようなものでした。
isshiki = (100, 'isshiki')
kawasaki = (101, 'kawasaki')
endo = (102, 'endo')
users = [isshiki, kawasaki, endo] # 何かのユーザー
for user in users:
print(f'{user[0]}: {user[1]}') # ユーザーのIDと名前を表示
「0」や「1」というインデックスを使えば、タプルの要素にアクセスできますが、それが意味するものはそもそものコードをちゃんと理解していないと分かりません。正解の例は全て「タプルの各要素が何のデータであるかが分かるような名前」を付けることで、コードをより分かりやすいものにしています。
では、それぞれについてカンタンに見てみましょう。
for文でアンパック代入する
アンパック代入を使うコードは以下のようなものでした。
isshiki = (100, 'isshiki')
kawasaki = (101, 'kawasaki')
endo = (102, 'endo')
users = [isshiki, kawasaki, endo] # 何かのユーザー
for user_id, user_name in users:
print(f'{user_id}: {user_name}') # ユーザーのIDと名前を表示
コードの基本構造は問題文のものと同じです。違うのはfor文で反復するリストの要素(タプル)を2つのループ変数にアンパック代入しているところ。このときにループ変数にuser_id/user_nameという名前を付けることでタプルの各要素が何を表しているかを明確にしています。最小限のコードの修正で可読性が高まるのがよいところです。
名前付きタプル(collections.namedtuple)を使う
名前付きタプルはcollectionsモジュールにあるnamedtuple関数を使うものです。
from collections import namedtuple
User = namedtuple('User', ['id', 'name'])
isshiki = User(100, 'isshiki')
kawasaki = User(101, 'kawasaki')
endo = User(102, 'endo')
users = [isshiki, kawasaki, endo]
for user in users:
print(f'{user.id}: {user.name}')
名前付きタプルは「namedtuple('typename', ['attr0', 'attr1', ……])」のように呼び出すことで「attr0」「attr1」という属性を持つ「typename」というクラスが定義されます。これはPythonのタプルのサブクラスなので、タプルと同様に軽量なことがそのメリットになります。また、その要素は変更不可能(イミュータブル)でもあります。このクラスのインスタンスは「typename(attr0, attr1)」のような呼び出しにより作成されます。
軽量であるタプルのよさを失わないままに、その要素に属性名としてアクセスできるのでこれもまたコードの可読性が高まります。注意するところがあるとすれば、名前付きタプルはその要素が変更不可能な点です。問題文のコードはそもそもがタプルを要素とするリストになっていたので構わないのですが、変更可能なデータ構造を作成するつもりで名前付きタプルを使わないようにしましょう(そうした場合は後述のデータクラスを使うのがよいでしょう)。
タプルじゃなくて辞書を使う
辞書を使うコードは以下のような感じ。
isshiki = {'id': 100, 'name': 'isshiki'}
kawasaki = {'id': 101, 'name': 'kawasaki'}
endo = {'id': 102, 'name': 'endo'}
users = [isshiki, kawasaki, endo]
for user in users:
print(f'{user["id"]}: {user["name"]}')
こちらは、その値が何なのかをキーを使って表現します。これも可読性を高めてくれますが、角かっこ「[]」とキーを囲むクオート文字が必要になるので、タイピング量は他の方法よりも多くなります。名前付きタプルやデータクラスでは、型定義のコードが必要になるので、このくらい短いコードだとどっちもどっちではありますが、データ量が多いのであれば名前付きタプルやデータクラスの方がトータルのタイピング量は減ると思われます。
また、Visual Studio Codeのような高機能なエディタや何らかの統合開発環境を使ってコードを書いている場合、Pythonのような動的型付き言語であっても、コードの静的な解析機能によって構文エラーのチェックが行われます。名前付きタプルやデータクラス、アンパック代入ではこの機能によってタイプミスを事前にチェックできますが、辞書のキーにタイプミスがあった場合、そこまでチェックしてもらえるかどうかは分かりません。このことには注意が必要かもしれません。
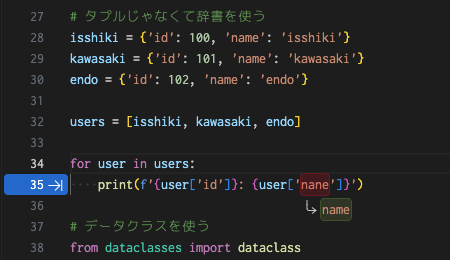 Visual Studio Codeは間違ったキーでも見つけてくれる優れもの
Visual Studio Codeは間違ったキーでも見つけてくれる優れものデータクラスを使う
データクラスはdataclassesモジュールのdataclassをデコレータとして使って、クラスを定義するものです。以下のようなコードになります。
from dataclasses import dataclass
@dataclass
class User:
id: int
name: str
isshiki = User(100, 'isshiki')
kawasaki = User(101, 'kawasaki')
endo = User(102, 'endo')
users = [isshiki, kawasaki, endo]
for user in users:
print(f'{user.id}: {user.name}')
こちらは@dataclassデコレータを付けたクラス定義の中に型ヒントの形で属性の名前とその型を指定します。これにより、暗黙のうちにインスタンスを初期化する__init__に加えて、__repr__、__eq__などの特殊メソッド(の幾つか)が自動的に生成されます。
データクラスを使った場合は、名前付きタプルを使った場合と同様、属性の形でその要素にアクセスできます。また、それらには型ヒントとして受け入れる値の種類を指定するので、静的解析ツールによるコーディング時のミスを発見しやすくなるのがデータクラスを使う上でのメリットになります(適切でない値の代入やタイプミスなど)。
名前付きタプルとの違いとしては、データクラスはデフォルトでその属性を変更可能であること、各種の特殊メソッドの自動生成、型ヒントの付与などが挙げられます。特に大量の変更可能なデータをまとめて処理するという場合には、データクラスの使用がオススメです。
まとめると……
というわけで、今見た4つの方法について表にまとめます。今回の問題に関していえば、どれを使っても正解といってよいでしょうが、実際には状況に応じてどれを使えばよいかが決まることになると思われます。
| メリット | デメリット | |
|---|---|---|
| アンパック代入 | シンプルで元のコードからの変更点が少ない | for文の外側ではインデックスアクセスが必要 |
| 名前付きタプル | 属性としてアクセス可/軽量/変更不可能 | 変更不可能なことに注意が必要 |
| 辞書 | キーを使って値にアクセス | キーのタイプミスに注意/タイピング量が多くなる |
| データクラス | 属性としてアクセス可/特殊メソッドの自動生成/デフォルトで変更可能 | 名前付きタプルよりもメモリ使用量は増える |
| 4つの方法のメリット/デメリット | ||
データ量が少なければアンパック代入がシンプルでよい解決策でしょう。辞書には柔軟性があります。例えば、新しいキーを追加すれば、新しい要素の追加が簡単に行えます。名前付きタプルはタプルのサブクラスであることの軽量さに加えて属性でアクセスできるのが魅力です。ただし、要素は変更不可能であることには注意が必要です。大量の読み込み専用のデータを扱うには、これが向いていると思われます。データクラスは、型ヒントを用いることでエディタや統合開発環境でのコーディング支援機能の恩恵を受ける可能性が大いに高まるとともに、特殊メソッドが自動生成されることからコードが簡潔なものになることが期待できます。大量の変更可能なデータを扱うのであれば、データクラスが一番の候補といえるでしょう。
というわけで、3つのLLMが推奨するやり方がどれだったかをお知らせします。
ChatGPTはなんと! 「時と場合による」と虹色という解答でした。まとめると以下のようになります。
- アンパック代入:軽いスクリプトや一時的処理ではこれがよい
- 名前付きタプル:不変のデータを読みやすく扱いたいときにはコレ
- 辞書:JSON(JavaScript Object Notation)的なデータを扱って外部のAPIとやりとりするときにオススメ
- データクラス:中規模から大規模なコードや拡張性が必要ならデータクラスを使う
Geminiは可読性の高さ、型ヒントがあること、デフォルトでは変更可能だけどオプションで変更不可能にもできる柔軟性の高さ、コードが簡潔になることなどからデータクラスが最もよい方法だと結論付けています。
Claudeは次のような順位を付けてくれました。
- データクラス:型ヒント/特殊メソッドの自動生成など、モダンでPythonic
- 名前付きタプル:タプルの不変性を維持、属性としてアクセス可、軽量
- アンパック代入:最小限の修正で済む
- 辞書:柔軟性は高いけど、この場面では不要かな
大量のデータがあるなら、データクラスか名前付きタプルを使って、最小限の修正で済ませたかったらアンパック代入を使うのがよいというのがLLMたちの結論です。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。