最後に、MRTGを利用した具体的なシステム情報監視の設定例を紹介します。
今回はWebサーバを監視エージェントとし、下表の値を監視・グラフ化します。「トラフィック量」「ディスクI/O」以外の4項目に関しては閾値を設定し、値に異常が検出された場合は管理者あてにメール通知するように設定します。
|
監視パラメータ
|
第1パラメータ
|
第2パラメータ
|
データ取得
|
正常値
|
障害検知後
の処理
|
| トラフィック量 |
受信bit数 |
送信bit数 |
SNMP経由 |
-※1
|
-※1
|
CPU
ロードアベレージx100 |
1分間の平均値 |
15分間の平均値 |
SNMP経由 |
100
以下 |
管理者に
メール通知 |
httpdの
プロセス数 |
現在の
プロセス数 |
現在の
プロセス数※2 |
SNMP経由 |
50以下 |
管理者に
メール通知 |
ディスク使用
状況 |
/usrの使用率 |
/varの使用率 |
SNMP経由 |
80%
以下 |
管理者に
メール通知 |
| メモリ使用状況 |
実メモリの
空き領域 |
Swapの空き領域 |
SNMP経由 |
50%
以下 |
管理者に
メール通知 |
| ディスクI/O |
読み取り
ブロック数 |
書き込み
ブロック数 |
ssh経由※3 |
-※1
|
-※1
|
※1:「トラフィック量」「ディスクI/O」は特に閾値の設定はしていません。
※2:MRTGでは必ず2つのパラメータを利用するため、第1、第2パラメータともhttpdのプロセス数としています。
※3:ディスクの負荷状況を測るためディスクI/O状況を取得しますが、このデータはSNMP経由では取れないため、ssh経由で情報を取得します。 |
トラフィック量、CPUのロードアベレージ、メモリ使用状況などは標準の状態でデータ取得が可能ですが、httpdのプロセス数やディスクの使用状況などを取得するにはエージェント側でSNMPの設定が必要になります。ここでは監視されるエージェント側に必要な設定を説明します。
Apacheなど多くのソフトウェアでは、処理を高速化するために複数のデーモンプロセスを起動し、クライアントからの要求を並列に処理します。例えば、Apacheの設定ファイルであるhttpd.confでは、以下の項目で起動プロセス数を調整可能です。
| httpd.confのディレクティブ |
説明 |
| MinSpareServers 5 |
あらかじめ待機させておくhttpdの最少数。Apacheは定期的にhttpdの起動プロセス数を監視し、この値を下回っていた場合は自動的にhttpdが起動される |
| MaxSpareServers 10 |
あらかじめ待機させておくhttpdの最大数。Apacheは定期的にhttpdの起動プロセス数を監視し、この値を上回っていた場合は自動的にhttpdが停止される |
| StartServers 5 |
Apache起動時に立ち上げるhttpdの数の設定 |
| MaxClients 150 |
同時に起動できるhttpdの総数 |
|
動作中のhttpdの総数をSNMPによって採取する場合は、SNMPエージェント側の設定が必要です。具体的には、SNMPエージェント側のsnmpd.conf内に以下のような記述を追記します。
設定後、snmpdを再起動すれば監視マネージャ側から以下のコマンドを実行することでhttpdの起動プロセス数に関する情報を取得できます。
# snmpwalk -c コミュニティ名 ホスト名 .1.3.6.1.4.1.2021.2.1
UCD-SNMP-MIB::prIndex.1 = INTEGER: 1
UCD-SNMP-MIB::prNames.1 = STRING: httpd
UCD-SNMP-MIB::prMin.1 = INTEGER: 0
UCD-SNMP-MIB::prMax.1 = INTEGER: 0
UCD-SNMP-MIB::prCount.1 = INTEGER: 8
UCD-SNMP-MIB::prErrorFlag.1 = INTEGER: 0
UCD-SNMP-MIB::prErrMessage.1 = STRING:
UCD-SNMP-MIB::prErrFix.1 = INTEGER: 0
UCD-SNMP-MIB::prErrFixCmd.1 = STRING: |
ただし、net-snmpのバージョンによってはDSOサポート付きのApacheのプロセス名を「libhttpd.ep」と指定する必要があったり、
以下のようにフルパスで指定する必要があります。
proc /usr/local/apache/bin/httpd |
設定後、snmpwalkコマンドでプロセス数が取得できるか否か、確認しましょう。
ディスクの使用状況を確認する場合も、snmpd.confの設定を変更する必要があります。具体的には以下のような設定を追加します。
設定後、snmpdを再起動すれば監視マネージャ側から以下のコマンドを実行することでディスクに関する情報を取得できるようになります。
# snmpwalk -v 1 -c コミュニティ名 ホスト名 .1.3.6.1.4.1.2021.9.1
UCD-SNMP-MIB::dskIndex.1 = INTEGER: 1
UCD-SNMP-MIB::dskIndex.2 = INTEGER: 2
UCD-SNMP-MIB::dskPath.1 = STRING: /usr
UCD-SNMP-MIB::dskPath.2 = STRING: /var
UCD-SNMP-MIB::dskDevice.1 = STRING: /dev/hda2
UCD-SNMP-MIB::dskDevice.2 = STRING: /dev/hda3
UCD-SNMP-MIB::dskMinimum.1 = INTEGER: 100000
UCD-SNMP-MIB::dskMinimum.2 = INTEGER: 100000
UCD-SNMP-MIB::dskMinPercent.1 = INTEGER: -1
UCD-SNMP-MIB::dskMinPercent.2 = INTEGER: -1
UCD-SNMP-MIB::dskTotal.1 = INTEGER: 28625036
UCD-SNMP-MIB::dskTotal.2 = INTEGER: 2015824
UCD-SNMP-MIB::dskAvail.1 = INTEGER: 20505344
UCD-SNMP-MIB::dskAvail.2 = INTEGER: 1786620
UCD-SNMP-MIB::dskUsed.1 = INTEGER: 6665612
UCD-SNMP-MIB::dskUsed.2 = INTEGER: 126804
UCD-SNMP-MIB::dskPercent.1 = INTEGER: 25
UCD-SNMP-MIB::dskPercent.2 = INTEGER: 7
UCD-SNMP-MIB::dskPercentNode.1 = INTEGER: 1
UCD-SNMP-MIB::dskPercentNode.2 = INTEGER: 0
UCD-SNMP-MIB::dskErrorFlag.1 = INTEGER: 0
UCD-SNMP-MIB::dskErrorFlag.2 = INTEGER: 0
UCD-SNMP-MIB::dskErrorMsg.1 = STRING:
UCD-SNMP-MIB::dskErrorMsg.2 = STRING: |
MRTGはSNMPを利用してデータを取得するのが基本動作ですが、監視対象がsshデーモンを実装できるLinuxサーバなどに限られるのであれば、かなり柔軟に統計情報を取得することが可能です。というのも、MRTGでは単に2つのデータをグラフ化しているにすぎないので、SNMPに限らず何らかの方法で統計情報を取得できればいいわけです。
ここでは、sshで監視対象ホストの/proc/statを閲覧し、そこからディスクI/Oに関するデータを取得できるようにしてみます。そのために、ssh接続を公開鍵認証方式で行えるようにします。具体的には、ssh-keygenを利用してsshの公開鍵ペアを作成します。このとき、パスフレーズには何も入力せず、秘密鍵を暗号化しないようにしておきます。
# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
a5:90:54:28:39:37:ea:04:21:7e:1a:9f:bd:0b:7c:a3 [email protected] |
これにより、/root/.ssh以下にid_rsa(秘密鍵)とid_rsa.pub(公開鍵)が作成されます。監視エージェント側で作成したid_rsa.pub(公開鍵)をauthorized_keys(認証用ファイル)に登録しておけば準備完了です。
# cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys |
上記の準備をしたうえで、id_rsa(秘密鍵)を監視マネージャ側に保存しておけば、監視マネージャ側から監視エージェントのあらゆる情報をssh経由で取得できるようになります。
特に、sshでのリモートアクセスが標準的になっているLinuxサーバが監視対象になる場合であれば、非常に有効な方法です。監視対象のホスト上で実行可能なコマンドであれば何でも利用できますし、sshでリモート管理できるサーバであれば、あらためてSNMPをインストールしたりSNMP用のポートをLISTENする必要がなくなります。
監視項目をすべて網羅するように、MRTGの設定ファイルを作成します。具体的には以下のような設定ファイルになります。このファイルでは、監視エージェントのコミュニティ名を「public」、IPアドレスを「192.168.0.2」としています。
WorkDir: /usr/local/apache/htdocs/mrtgtest
Language: eucjp
IconDir: /mrtg/icons/
RunAsDaemon: Yes
Interval 5
SetEnv[^]: HOST="myhost.mydomain"
#-----------------------------------------------------------------
# 閾値を超えた場合のスクリプトの定義
# どのパラメータを対象とする場合も同じスクリプトを利用する
#-----------------------------------------------------------------
ThreshDir: /usr/local/apache/htdocs/mrtgtest/threshdir
ThreshProgI[_]: /usr/local/mrtg-2/bin/mail_warning.pl
ThreshProgO[_]: /usr/local/mrtg-2/bin/mail_warning.pl
ThreshProgOKI[_]: /usr/local/mrtg-2/bin/mail_recovery.pl
ThreshProgOKO[_]: /usr/local/mrtg-2/bin/mail_recovery.pl
#-----------------------------------------------------------------
# 取得したデータをそのまま(差分を取らずに)利用するものから設定する
# グラフのOptionsとしてgaugeを指定
#-----------------------------------------------------------------
Options[_]: growright,gauge
#-----------------------------------------------------------------
# httpdプロセス数の数(グラフ化するのはhttpdプロセス数のみ)
#-----------------------------------------------------------------
Target[httpd]: .1.3.6.1.4.1.2021.2.1.5.1&.1.3.6.1.4.1.2021.2.1.4.1:
[email protected]:
ThreshMaxI[httpd]: 20
SetEnv[httpd]: EMAIL="[email protected]"
URL="http://192.168.0.2/mrtg/httpd.html"
MaxBytes[httpd]: 150
Title[httpd]: Number of httpd
PageTop[httpd]: <H1> Number of httpd on WebServer</H1>
YLegend[httpd]: Number of httpd
ShortLegend[httpd]: httpd
LegendI[httpd]:起動中のhttpd
LegendO[httpd]:起動中のhttpd
#-----------------------------------------------------------------
# CPUのロードアベレージ x 100
# (グラフ化するのは1分間平均 x 100、および15分平均 x 100)
# ShortLegend[la]の値は全角スペースを指定し、単位なしにする
#-----------------------------------------------------------------
Target[la]: .1.3.6.1.4.1.2021.10.1.5.1&.1.3.6.1.4.1.2021.10.1.5.3:
[email protected]:
ThreshMaxI[la]: 50
SetEnv[la]: EMAIL="[email protected]"
URL="http://192.168.0.2/mrtg/la.html"
MaxBytes[la]: 100
Title[la]: Load Average
PageTop[la]: <H1> Load Average on WebServer</H1>
YLegend[la]: Load Average
ShortLegend[la]:
LegendI[la]:1分平均
LegendO[la]:15分平均
#-----------------------------------------------------------------
# ディスク使用状況
# (グラフ化するのはAgent側で設定した/usrおよび/varの使用率)
#-----------------------------------------------------------------
Target[df]: .1.3.6.1.4.1.2021.9.1.9.1&.1.3.6.1.4.1.2021.9.1.9.2:
[email protected]:
ThreshMaxI[df]: 80
SetEnv[df]: EMAIL="[email protected]"
URL="http://192.168.0.2/mrtg/df.html"
MaxBytes[df]: 100
Title[df]: Disk Usage "/usr" and "/var"
PageTop[df]: <H1>Disk Usage "/usr/local" and "/var" on WebServer</H1>
YLegend[df]: Disk Usage
ShortLegend[df]: %
LegendI[df]:/usr
LegendO[df]:/var
#-----------------------------------------------------------------
# メモリ使用状況(グラフ化するのは実メモリおよびスワップの空き領域)
# MaxByteには実験機の総スワップ量を指定
#-----------------------------------------------------------------
Target[mem]: .1.3.6.1.4.1.2021.4.4.0&.1.3.6.1.4.1.2021.4.6.0:
[email protected]:
ThreshMinO[mem]: 50
SetEnv[mem]: EMAIL="[email protected]"
URL="http://192.168.0.2/mrtg/mem.html"
MaxBytes[mem]: 1052216
Title[mem]: Available Memory ("real" and "swap")
PageTop[mem]: <H1>Available Memory "real" and "swap" on WebServer</H1>
YLegend[mem]: Available Memory
ShortLegend[mem]: kbyte
LegendI[mem]:実メモリ利用可能量
LegendO[mem]:Swap利用可能量
#-----------------------------------------------------------------
# 以降のパラメータはカウンタ値。Optionsのデフォルト値を書き換え
#-----------------------------------------------------------------
Options[_]: growright
#-----------------------------------------------------------------
# ディスクI/O状況
# /usr/local/mrtg-2/bin/disk_io.plでディスクI/Oを取得する
#-----------------------------------------------------------------
Target[disk_io]: `/usr/local/mrtg-2/bin/disk_io.pl`
MaxBytes[disk_io]: 200
Title[disk_io]: Disk I/O
PageTop[disk_io]: <H1>Disk I/O on WebServer</H1>
YLegend[disk_io]: Disk I/O
ShortLegend[disk_io]: blocks/s
LegendI[disk_io]:読取ブロック数
LegendO[disk_io]:書込ブロック数
#-----------------------------------------------------------------
# トラフィック状況
#-----------------------------------------------------------------
Target[traffic]: 2:[email protected]:
MaxBytes[traffic]: 1250000
Title[traffic]: Traffic
PageTop[traffic]: <H1> Traffic on WebServer</H1> |
ディスクI/Oはssh経由で取得します。そのためのPerlスクリプト/usr/local/mrtg-2/bin/disk_io.plを以下のように作成します。ここでは、/proc/statのディスクI/Oに関するデータを利用します。
cpu 12904636 51986911 8322655 692726416
cpu0 12904636 51986911 8322655 692726414
page 17554722 340260707
swap 48302 37080
intr 3959533365 3921615964 128 0 7760430 1 0 7 753 3 1 1 0 20 0 30156057 0
disk_io: (3,0):(32415286,1839036,35108808,30576250,680521384)
ctxt 188367002
btime 1050552000
processes 10140302 |
| /proc/statの出力例 |
本来、「第1パラメータ値」「第2パラメータ値」「稼働時間」「ホスト名」の4つのパラメータを出力する必要がありますが、「稼働時間」「ホスト名」はそれほど重要なデータではないため、このスクリプトでは3、4行目の出力は空行を返すようにしています。
#!/usr/bin/perl
open(SSH,"ssh 192.168.0.2 cat /proc/stat|");
while(<SSH>){
if (/^disk_io: \([^(]+\([0-9]+,[0-9]+,([0-9]+),[0-9]+,([0-9]+)\)/){
print "$1\n";
print "$2\n\n\n";
}
}
close(SSH); |
- 異常値検出時と正常値回復時に実行するスクリプトの作成
監視パラメータが閾値を超えた場合は、異常を検出して管理者にメールで通知するスクリプトを作成しておきます。また、検出した値が正常値に戻った場合のスクリプトも併せて作成します。
ここでは、
- 対象とするパラメータ名
- 閾値
- 現在のパラメータ値
- MRTGのURL
をメールで管理者あてに送信するものとします。
#!/usr/bin/perl
$to = $ENV{'EMAIL'};
$from = "mrtguser\@myhost.mydomain";
$subject = "[ Warning ] $ARGV[0] on $ENV{'HOST'}";
open(MAIL,"|/usr/bin/nkf -j | /usr/sbin/sendmail -t $to -f $from");
print MAIL "From: $from\n";
print MAIL "To: $to\n";
print MAIL "Subject: $subject\n\n";
print MAIL `date` . "$ARGV[0] が閾値 を超えました。\n";
print MAIL "------------------------------------------------- \n";
print MAIL " 閾値 : $ARGV[1] \n";
print MAIL " 現在の値 : $ARGV[2] \n";
print MAIL "------------------------------------------------- \n\n";
print MAIL "$ENV{'URL'} \n";
foreach(@ARGV){
print MAIL $_;
}
close(MAIL); |
| 異常を検出した際に実行するスクリプト |
#!/usr/bin/perl
$to = $ENV{'EMAIL'};
$from = "mrtguser\@myhost.mydomain";
$subject = "[ Recovery ] $ARGV[0] on $ENV{'HOST'}";
open(MAIL,"|/usr/bin/nkf -j | /usr/sbin/sendmail -t $to -f $from");
print MAIL "From: $from\n";
print MAIL "To: $to\n";
print MAIL "Subject: $subject\n\n";
print MAIL `date` . "$ARGV[0] が正常値に戻りました。\n";
print MAIL "------------------------------------------------- \n";
print MAIL " 閾値 : $ARGV[1] \n";
print MAIL " 現在の値 : $ARGV[2] \n";
print MAIL "------------------------------------------------- \n\n";
print MAIL "$ENV{'URL'} \n";
close(MAIL); |
| 異常が正常に戻った際に実行するスクリプト |
前述したMRTGの設定ファイルを利用すると、各監視項目に対するHTMLファイルが別々に作成されます。このままではWebブラウザでそれぞれのHTMLファイルを参照するのが非常に面倒です。
これを解決してくれるのが、MRTGに用意されているindexmakerというスクリプトです。このファイルは多くのデータを監視する場合に非常に有用なもので、MRTGの設定ファイルを読み込んで複数のHTMLファイルへのリンクを持ったインデックスファイルを作成してくれます。以下のように、MRTGの設定ファイルを引数にして実行し、得られた出力を/usr/local/apache/htdocs/mrtg/index.htmlとして保存すればよいでしょう。
# /usr/local/mrtg-2/bin/indexmaker /usr/local/mrtg-2/lib/mrtg.cfg > /usr/local/apache/htdocs/mrtg/index.html |
これにより、各統計データへのリンクが張られた以下のようなインデックスページが作成されます。
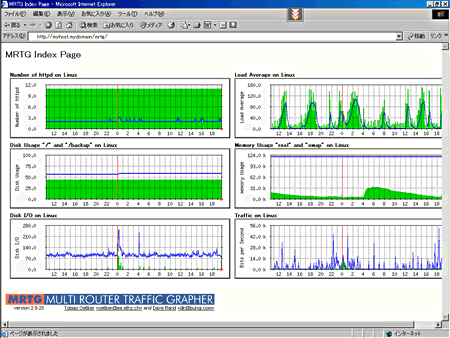 作成されたインデックスページ(画像をクリックすると拡大表示します)
作成されたインデックスページ(画像をクリックすると拡大表示します)
今回は、Linuxマシンを対象にSNMPやsshを利用して統計データを取得し、MRTGでグラフ化する方法を説明しました。MRTGは柔軟な設定ができる分、多少設定項目が多く複雑です。1台のサーバを監視するためにこれだけの手間を掛けるのは面倒だと考える方も多いかもしれません。
ただし、統計データを継続的に取っておくとさまざまなメリットがあることは間違いありません。ネットワークやサーバが何となくおかしいと思った際は、このような統計情報が原因究明に役に立ちます。特にサーバ管理に携わるのが初めての方は、自分が管理しているサーバがどのような挙動をしているのか、どのような場合にネットワークの異常を来すのかなど、いままで見えていなかった新たな発見もあると思います。
本連載では、サーバを管理・運用するための手法を紹介してきました。この連載が、少しでもサーバの管理・運用を始める方の手助けになれば幸いです。




