Facebook、「Minecraft」内でAIアシスタントを実装できる「CraftAssist」を公開:機械学習では難しい領域にチャレンジ
Facebookは、「Minecraft」内で人間のプレーヤーと協力して動くAIアシスタントを実装するためのオープンソースプラットフォーム「CraftAssist」を公開した。人間のあいまいな要望をくみ取って動作できることが特徴だ。
Facebookは2019年7月18日(米国時間)、「Minecraft」内で人間のプレイヤーと協力して動くAIアシスタントを実装するためのオープンソースプラットフォーム「CraftAssist」を公開した。Minecraftは、広大な世界でブロックを置いて冒険を続けるサンドボックスゲーム。
CraftAssistで実装されるAIアシスタントは、人間のプレイヤーとテキストベースのチャットでコミュニケーションを取りながらブロックを置いたり壊したり、モブ(動物などのキャラクター)を生み出したりできる。このAIアシスタントは言語や知覚、記憶、物理的アクションを組み合わせて、家造りのような複雑なタスクを実行できる。
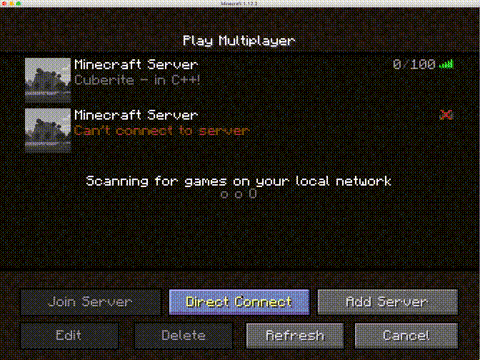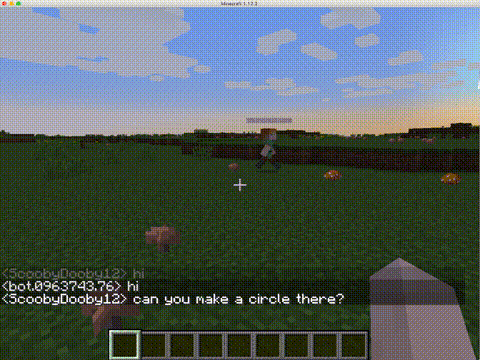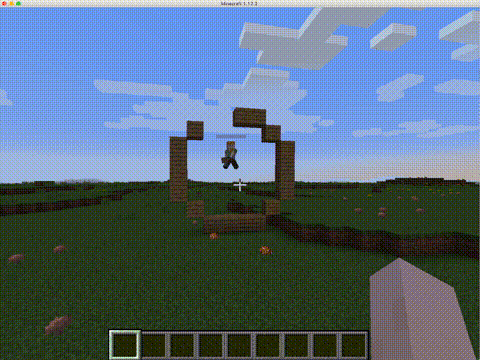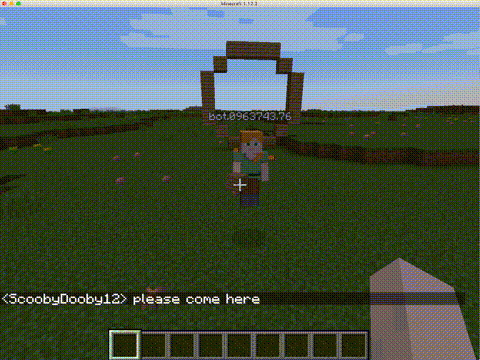
Facebookは次のような目的を持ってAIアシスタントと実装プラットフォームを開発した。会話で指定されたタスクを完了でき、最終的には会話のやりとりから学習できるエージェントの研究を支援することだ。
AI研究コミュニティーによるCraftAssistの利用を促進するために、成果物をオープンソース化した。フレームワークやベースラインアシスタント、開発に使ったツールとデータが対象だ。例えば人間のプレイヤーがMinecraftで家屋を造る過程のステップバイステップデータ、家屋のセマンティックセグメンテーションデータ(画素単位で物体を認識したデータ)、大規模な自然言語セマンティック解析データセットなどだ。
CraftAssistの仕組み
CraftAssistは、オープンソースの拡張可能なMinecraft互換ゲームサーバ「Cuberite」を使用する。プレイヤーは標準のMinecraftクライアントとなって、AIアシスタントとやりとりする。研究者はゲーム内の全ての言葉とアクションを含むゲームセッションを記録し、独自のトレーニングデータを生成できる。
FacebookはCraftAssistに含めたベースラインアシスタントを次のようにしてトレーニングした。
まず、あまりトレーニングされていないアシスタントと人間とのやりとりを記録したデータセットを用意した。次にクラウドソースによって参加したユーザーが作り出した2500軒以上の家造り例のデータセットを使った。これらのトレーニングデータセットはオープンソースとして公開されている。
ベースラインアシスタントはモジュラー設計を採っているため、研究者はAIアシスタント全体を実験に使うことができ、さらに記憶や知覚、言語理解などに関連するコンポーネントを個別に使うこともできる。
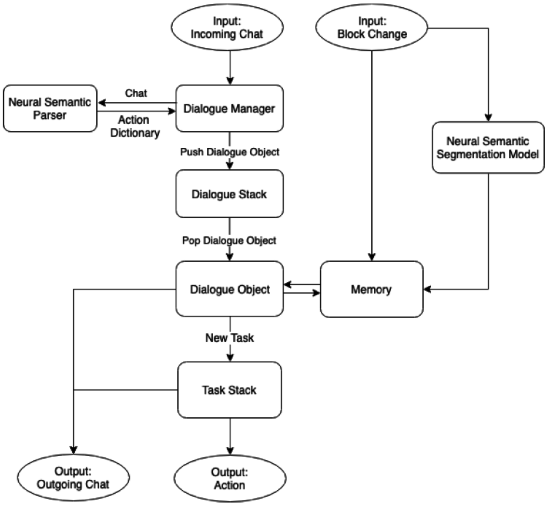
これらのコンポーネントモジュールは協調して機能する。例えば、人間のプレイヤーが、「青い立方体の隣に家を建ててほしい」とAIアシスタントに頼むと、言語理解や記憶、知覚モジュールなどが連携し、データセットの家造り例を参考にして、依頼されたタスクを実行する。
機械学習を超えて
今回の研究の目的は、AIアシスタントをさまざまな状況に柔軟に対応できるようにすることだ。
機械学習(ML)は限定された領域では目を見張るような成果を打ち出している。だが、Facebookによれば、多種多様なタスク、特に人間が言語を使用して指示を下すタスクにおいては進展があまり見られない。
Minecraftを用いた研究から得られた教訓は、さまざまな現実世界のシナリオで人間とAIとの対話や協力を改善する可能性があるとした。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 MITの研究チーム、画像内のオブジェクトを音声によって識別する機械学習システムを開発
MITの研究チーム、画像内のオブジェクトを音声によって識別する機械学習システムを開発
マサチューセッツ工科大学(MIT)の研究者チームは、画像内のオブジェクトを画像の音声説明に基づいて識別する機械学習システムを開発した。「Siri」などとは異なり、あらかじめ何千時間分もの音声録音の文字起こしを必要とせず、話者の少ない言語にも拡張しやすい。 「音」と「振動」で分かるモノやヒトの状態、安価に実現する2つの手法
「音」と「振動」で分かるモノやヒトの状態、安価に実現する2つの手法
カーネギーメロン大学の研究チームは、周囲で何が起こっているかを音や振動状態から認識できる安価な2つの手法を開発した。これらの手法を用いると、モノやヒトの状態が分かるだけでなく、モノを入力デバイスとして利用できるという。 複数話者でも個別に音声をテキストへ、日立が音源分離技術を製品化
複数話者でも個別に音声をテキストへ、日立が音源分離技術を製品化
日立製作所は会話音声をテキスト化する「音声書き起こし支援サービス」の販売を開始した。雑音が含まれていたり、複数人の音声が重なっていたりしても、話者を識別して、話者ごとに分離したテキストを生成できる。