Loading
|
||
|
Loading
|
| @IT > Oracle RACフェイルオーバーを高速化するSGeFF |
|
|
前回の「Oracle RAC 10g+HP Serviceguardの勘どころ」では、クラスタウェアHP ServiceguardとOracle RACの組み合わせによりフェイルオーバー時間を最適化する技法を紹介した。HPから昨年6月より提供されているServiceguard Extension for Faster Failover(以下、SGeFF)は、このHP Serviceguardのフェイルオーバーをさらに高速化するオプション製品である。SGeFFを使えば、クラスタの再構成にかかる時間を「数秒程度」にまで短縮可能だ。ここでは、SGeFFがどのようにして大幅な時間短縮を実現するのか、その動作メカニズムを掘り下げてみたい。
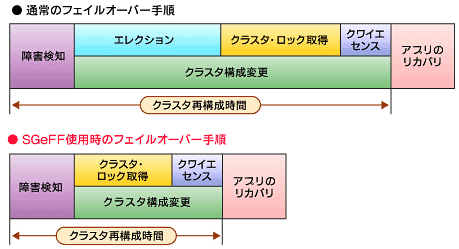
Serviceguardの歴史は、「クラスタ再構成」の時間短縮の歴史といえる。まずは、図1を見ていただきたい。
図1が示すように、「障害の発生」から「サービスの回復」までのフェイルオーバー時間には、以下の2つの処理が含まれる。
「クラスタ再構成」とは、障害を検知してから、クラスタをどのように再構成すればよいか決定するまでのプロセスである(その詳細については、HP-UX技術情報サイトHP-UX Developer Edgeの記事「HAクラスタの疑問を解く・後編」に解説がある)。 一方、「そのほかのリカバリ処理」としては、共有ディスクの活性化やデータベースの再起動(シングル・インスタンスの場合)、データベースのクラッシュ・リカバリが含まれる。この処理に要する時間はデータベースの規模や障害状況によって大きく変化するため、事前の予測は困難だ。 この2つの処理のうち、前者の「クラスタ再構成時間」を可能な限り短くするのが、クラスタウェアに課せられた使命だ。そこでServiceguardでは、後述するQuorum Serverや今回リリースされたSGeFFといったユニークな新技術を順次投入し、クラスタ再構成の高速化を達成してきた。最終的にSGeFFでは、クラスタ再構成時間が数秒程度にまで短縮されている。
では、なぜSGeFFではそれほどまでの高速化が可能になったのだろうか。図2は、通常のServiceguardとSGeFFのフェイルオーバー手順の違いを示した図である。
まず異なる点は、従来は必要であった「エレクション(election)」の手順がSGeFFでは省略されている点だ。「エレクション」とは、障害検出の後に生き残った各ノードが「新たに形成されるHAクラスタに参加する権利」を獲得するための手続きである。SGeFFでは、この手順を省略しつつも、ノード間の競合が発生しないメカニズムを実現している。 高速化されたもう1つの手順は、「クラスタ・ロック取得」である。クラスタ・ロックとは、新しいHAクラスタへの参加権をあらわすフラグのようなものだ。例えば「クラスタがちょうど半数ずつに分断された」としよう。この状況は「スプリット・ブレイン(split brain)」と呼ばれる。このときに実行されるのが、「クラスタ・ロックの取得」である。つまり、いずれか1つのノード・グループがクラスタ・ロックを先取りすることで、スプリット・ブレインを回避する仕組みである。SGeFFでは、その実装手段としてQuorum Serverの利用を必須とすることで、クラスタ・ロック取得時間を大幅に短縮している(これについて、詳しくは後述する)。 ではつづいて、SGeFFの導入の実際を詳しく見ていこう。
SGeFFを動作させるためには、以下の動作環境を用意する必要がある。
上述したとおり、SGeFFはServiceguardのオプション製品であり、最新バージョンである11.16以降で動作する。プラットフォームとしては、HP-UX 11i v1(11.11)もしくはHP-UX 11i v2(11.23)が動作するHP 9000サーバかHP Integrityサーバをサポートする。また、標準のServiceguardではオプション扱いであったQuorum Serverの利用が必須となる。 ちなみに、SGeFFをOracle RACのフェイルオーバーに使用する場合は、Serviceguardのもう1つのオプション製品であるServiceguard Extension for RAC(以下、SGeRAC)との併用が不可欠となる。なお、ServiceguardやSGeRACが必要とする以上のメモリおよびディスク容量、ポートなどをSGeFFが使用することはない。
SGeFFの設定方法は、Serviceguardのそれと大幅に異なる部分はない。設定方法が変化するのは、以下の3つのパラメータだ。
まず、SGeFF独自のパラメータとして、「FAILOVER_OPTIMIZATION」が追加された。同パラメータには「NONE」もしくは「TWO_NODE」のいずれかを指定でき、SGeFF利用時には後者を選択する。 残る2つは、いずれも既存パラメータである。1つ、ハートビートLANの設定を2系統について実施するためのパラメータ。もう1つは、必須となるQuorum Server設定を実施するパラメータである。
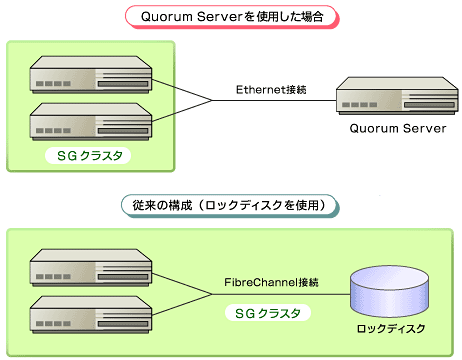
ここで、SGeFFによるクラスタ再構成の高速化において重要な役割を担っているQuorum Server(HP Serviceguard Quorum Server)についてあらためて説明しておこう。 Serviceguardでは、クラスタ・ロックを実現する手段として、以下の2つの方法をサポートしている。
ロック・ディスクとは、共有ディスクの特定領域をクラスタ・ロックとして利用する方法である。クラスタ・ロックを取得するノードは、ディスク領域にマークを付けることで、ロックの取得を表明する。一方、Quorum Serverは、HAクラスタ外部のノード上のソフトウェアによって実現されるクラスタ・ロックである。いずれも、スプリット・ブレインを解消するという役割は同じである。 Serviceguard以外のクラスタウェアでは、クラスタ・ロックの実装方法として、ロック・ディスクを用いるのが一般的だ。一方Serviceguardでは、Quorum Serverという独立したソフトウェアによって、クラスタ・ロックを実現することができる。このユニークな設計によって、クラスタ再構成時間の大幅な短縮、さらには可用性の向上を可能にしている。 Quorum Serverとロック・ディスク、いずれもクラスタ・ロックという役割は同じである。では、なぜ前者はクラスタ再構成の高速化に貢献するのだろうか。以下の表は、この両者の特徴を比較したものである。
ロック・ディスクとQuorum Serverの基本的な違いは、前者は共有ディスクによる実装であるのに対し、後者がソフトウェアによる実装である点だ。ロック・ディスクの場合は、FibreChannelなどのI/Oバスのリセットが必要であり、クラスタ・ロックの取得に数十秒の時間を要する。これに対しQuorum Serverの場合は、LAN経由で同サーバに接続するため、取得時間は数秒で済むのである。 また、クラスタ構成の自由度や多重障害発生時の修復方法にこの両者には差がある。ロック・ディスクは1つのクラスタしかサポートできないが、Quorum Serverは最大50クラスタを1台でサポート可能だ。ロック・ディスクの単一障害時は、どちらの場合でもServiceguardクラスタは継続動作するので可用性としては変わらない。が、多重障害等でクラスタ・ロックを交換する必要が生じた場合、ロック・ディスクの場合は、クラスタを止めて共有ディスクを修復する場合もありうるが、Quorum Server障害時はクラスタを止めずに交換できる。
このように、SGeFFのすばやいフェイルオーバーは、こうしたQuorum Serverの高速性とスケーラビリティ、高可用性に支えられて実現されていることがお分かりいただけたはずだ。 日本HPでは、このSGeFFとOracle 9i RACの組み合わせによるフェイルオーバー検証作業を実施した。その結果、クラスタ再構成にかかる処理が5秒程度にまで短縮されていることが確認された。この検証結果は、HP-UX Developer Edgeの記事「Oracle RACフェイルオーバーを高速化するSGeFF・後編 」にて公開されている。また同記事では、さまざまなトラブル状況を考慮したベスト・プラクティスも紹介しているので、Oracle RAC導入を検討されている方はぜひ参考にしていただきたい。
提供:日本ヒューレット・パッカード株式会社
企画:アイティメディア 営業局 制作:@IT 編集部 掲載内容有効期限:2005年6月9日 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||