Loading
|
||
|
Loading
|
| @IT > Oracle RAC 10g+HP Serviceguardの勘どころ |
|
|
Oracle Database 10gのクラスタ・テクノロジReal Application Clusters 10g(以下、RAC 10g)では、オラクルが開発したクラスタウェアCluster Ready Services(以下、CRS)の利用が必須となった。しかしCRSは、個々のOSレベルで最適化された障害検出やフェイルオーバーの能力は備えていない。そのためミッションクリティカル用途では、例えば業界標準のクラスタウェアであるHP ServiceguardとCRSを組み合わせて使うことで、より優れた可用性が得られる。ここでは、この両者の組み合わせの勘どころを探ってみたい。
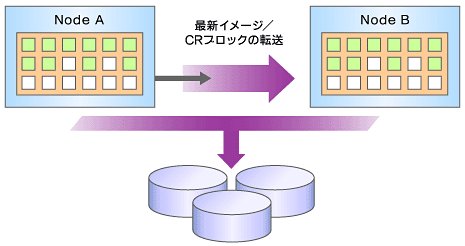
まずは、通常のHAクラスタ(高可用性クラスタ)とRACによるクラスタの違いについて再確認しておきたい。 ご存じのとおりHAクラスタでは、1台の共有ディスクを複数のノードに接続する構成が一般的である(HAクラスタについて詳しくは、HP-UX技術情報サイトHP-UX Developer Edgeの記事「HAクラスタの疑問を解く」を参照していただきたい)。たとえばHAクラスタ上でOracleデータベースを運用するケースを考えてみよう。プライマリ・ノードの障害時には、スタンバイ・ノード側で共有ディスクのボリュームをマウントし直したあと、Oracleインスタンスを起動する。その後、スタンバイ・ノードによってサービスが再開される。共有ディスク上のデータベースをオープンできるのは、つねに1つのノードに限定されている。 一方RACによるクラスタでも、1台の共有ディスクを複数のノードに接続するという構成は変わらない。異なるのは、すべてのノード上でOracleインスタンスが常時起動しており、それぞれが共有ディスク上のデータベースを同時にオープンしている点だ(図1)。もちろん、普通のデータベースでこのようなことをすれば、共有ディスクにI/O負荷が極端に集中するし、データの整合性も維持できない。
この2つの問題を解決するのが、RACの要である分散キャッシュ機能、Global Cache Service(以下、GCS)である。GCSは、各ノードのそれぞれのキャッシュを統合し、1つの仮想的なキャッシュ(Cache Fusion)を実現する。例えば、ノードBが必要とするデータがノードAのキャッシュにあるときは、ノードAからBへとキャッシュ内容が瞬時にネットワーク転送される。このメカニズムにより、共有ディスクがボトルネックとなることを防ぎ、クラスタ全体で優れたスケーラビリティが得られる。また同時に、各ノードがデータベース・レコードのロックを分散管理することで、データの整合性も確保される仕組みだ(図2)。
こうしたアーキテクチャの違いから、RACによるクラスタは、通常のHAクラスタでは得られない以下のようなメリットを提供する。
HAクラスタでのフェイルオーバーでは、Oracleインスタンスの起動のために数十秒〜数分の時間を要する。これに対し、RACではOracleインスタンスの起動はすべてのノードで動作しているため、あらためて起動する時間がかからない。さらにRACではCache Fusionによる負荷分散のおかげで、すべてのノードのプロセッサとメモリを活用でき、格段に高いスケーラビリティを実現できる。この2点がRACのアドバンテージである。
HAクラスタと同様に、RACにおいてもノードやネットワーク、Oracleインスタンスなどの障害をきっかけとしてフェイルオーバーが開始される。HAクラスタとは異なり、RACではOracleインスタンスの起動や共有ディスクのボリュームのマウントは不要だ。ただしそのほかのフェイルオーバー処理、例えば障害の検知をはじめ、スプリット・ブレイン(障害によりクラスタが分裂する現象)の解決、クラスタの再構成、IPアドレスの引き継ぎといった処理は、HAクラスタと同じく必要になる。またダウンしたOracleインスタンスの代わりを務めるOracleインスタンスでは、共有ディスク上に残されたREDOログをもとにトランザクションのロール・フォワードやキャッシュのリカバリなどを実施する。
Oracle RAC 10gからは、RACのフェイルオーバーを実現する手段として、オラクル製のクラスタウェアCluster Ready Service(CRS)が標準コンポーネントとし て提供されるようになった。 そこで以下ではCRSがどのように構成されているかを概観し、システム、OSレベルのイベント、RAC以外のアプリケーションの監視に必要となるそのほかのクラスタウェアと共存させる際に考慮すべきポイントを説明したい。本記事では、HP-UX対応クラスタウェアHP ServiceguardのOracle RAC対応版、Serviceguard Extension for RAC(以下、SGeRAC)との組み合わせを検証する。
CRSは、オラクルが開発したRAC専用のクラスタウェアである。あくまでRAC専用であるため、CRSが監視するのはもっぱらOracle関連のプロセスであり、そのほかのアプリケーションの監視には利用できない。
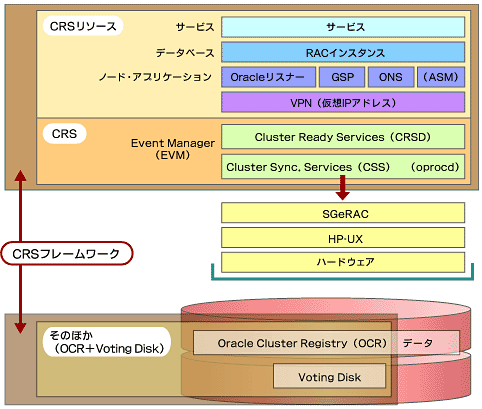
CRSは、以下の3種類のコンポーネントから構成されている。
図3は、HP-UX上でSGeRACとCRSを併用する場合のそれぞれの位置付けを示した図である。
以下、CRSの個々のコンポーネントについて概観しよう。
まずは、CRSリソースである。これはCRSが管理するさまざまなリソースの総称であり、SGeRACにおけるパッケージに相当する。具体的には以下のものが含まれる。
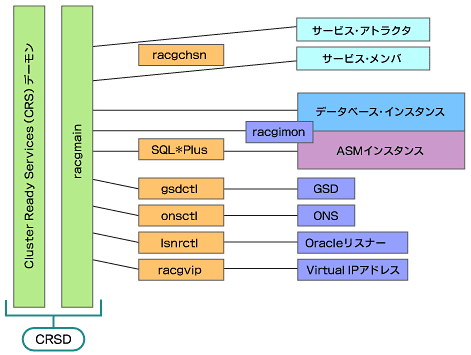
一方、これらのCRSリソースを管理するソフトウェアが、CRSデーモン群である。
以上のCRSリソースおよびCRSデーモン群以外に、以下のコンポーネントが存在する。
ここまで見てきたとおり、CRSはクラスタウェアとしての一通りの機能を備えている。とはいえ、CRSはいまのところ、SGeRACほどOSレベルで最適化された障害検出やフェイルオーバーの能力は備えていない。たとえばSGeRACでは、HP-UXイベント管理ツールHP EMS(Event Monitoring Service)との連携により、プロセッサやメモリ、NICカード、ディスクドライブなどのデバイス障害をOSレベルで検知し、即座にフェイルオーバーを開始できる。またSGeRACでは、業務で必要なジョブスケジュールを行うアプリケーションなど、RAC以外のアプリケーションの監視やフェイルオーバーが可能だ。 さらに、HP-UX対応のワークロード管理ツールHP WLM(Workload Manager)と組み合わせれば、データベースやWebサーバのレスポンス時間などを監視し、サービスレベルが一定値を下回った場合に強制的にフェイルオーバーさせることも可能だ。これに対し、CRSではOracle関連プロセスやハートビートの状態監視だけで障害を検知する。 またフェイルオーバー時間にも大きな差がある。HPから昨年6月より提供されている高速フェイルオーバー・オプションServiceguard Extension for Faster Failover(SGeFF)を使えば、障害検出からRACのフェイルオーバーまでが数秒で完了する。一方CRS単体の場合、デフォルトでは障害検出までに30秒を要し、またフェイルオーバーには数十秒程度かかる。こうした事情から、ミッションクリティカル環境でのRAC構成時には、いままで同様にSGeRACを併用するケースが少なくないだろう。 CRS+SGeRAC構成によって得られるメリットについてまとめると次のようになる。
日本HPと日本オラクルが共同運営する検証体制MC3(Mission Critical Certified Center)では、RAC 10gとSGeRACの組み合わせによるフェイルオーバーの実地検証を行った。この検証作業では、ノード障害やインスタンス障害、ネットワーク障害などのさまざまなパターンが実際に再現され、RACとSGeRACの連携によりフェイルオーバーを短縮可能なことが確認されている。 さらにMC3では、これらのさまざまなケースにおいて最良の結果を得られるベスト・プラクティスを紹介している。このMC3による検証レポートは、HP-UX Developer Edgeの記事「Oracle RAC 10g+HP Serviceguardの勘どころ・後編 」にて詳しく説明されているので、興味のある方はぜひ参照していただきたい。
提供:日本ヒューレット・パッカード株式会社
企画:アイティメディア 営業局 制作:@IT 編集部 掲載内容有効期限:2005年6月9日 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||