
NVIDIA Tesla 10
次に、NVIDIA Tesla 10(以下T10)を見ていきましょう。T10はGPGPU用ボードであるNVIDIA Teslaシリーズに採用されている演算チップです。
GPGPU(General Purpose GPU)というのは、これまで3Dグラフィックのみに使われてきたGPUを一般的な用途(General Purpose)にも利用しようというプログラミング手法です。
GPGPUについて理解するにはGPUの歴史について少し知る必要があります。かつてはGPUというのは、頂点(Vertex)を示す座標の位置を変換してその座標で決められる三角形の中を一定のルールに従って塗り潰すというハードウェアでした。
しかし、グラフィックに対する要求は単純に表示できればよいというものから、もっとリアルに、もっと面白い画像を出したいと、年々高度になり、座標の変換や、塗り潰しのルールをプログラムによって制御できるシェーダと呼ばれる仕組みが導入されました。このシェーダは最初は簡単なものだったのですが、時代の進歩とともに一般的なプログラムと比較してもそれほど違いのないレベルにまでなってきました。
また、3Dグラフィック処理というものが元からかなり並列性が高い処理であったこと、そして並列処理プロセッサの性能がシングルスレッドプロセッサの性能よりも向上させやすいことといったような背景があり、GPUは時代と共に、CPUよりも高速な汎用プロセッサになっていったのです。
そこで、それならば、その性能を3Dグラフィック以外にも活用しようということで生まれたのがGPGPUです。それではGPGPU向けプロセッサであるT10の並列に関する特徴をいくつか簡単に説明しましょう。
●SIMTアーキテクチャ
T10はSIMT(Single Instruction Multiple Thread)と呼ばれる一般的なプロセッサとは違うアーキテクチャを採用しています。SIMTは、汎用プロセッサにおけるSIMDとハードウェアマルチスレッドの中間的な構造をしており、1つの命令デコーダで複数の実行ユニットを制御しますが、SIMDとは違い各処理単位が独立したarchitectural stateを持ちます。図2にT10のSIMTのブロック図を示します。
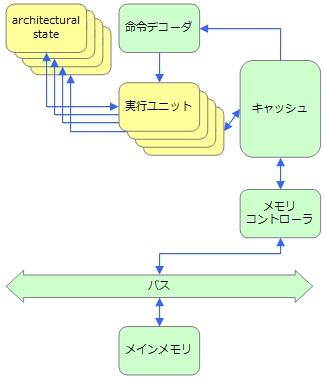
T10のSIMT上で動く各スレッドは独自のarchitectural stateを持っているため、各スレッドそれぞれが独自のループ処理や条件分岐を行うことが可能です。ただし、命令デコーダを共有しているため、各スレッドが独自の処理を行った場合並列実行にはなりません。T10の性能を引き出すためには、一定数(T10では32個)のスレッドが同じ命令を実行する必要があります。
●768個のハードウェアスレッド
T10は、768個のスレッドをハードウェアで管理し、切り換えることができます。Intelの最新プロセッサであるi7のスレッド数が2個であることと比較すると、768個のスレッドというのはかなり大きな数のように思えます。
これほどの数のスレッドを同時実行する理由は何なのでしょうか。その理由はT10のメモリ構成にあります。
T10は一般的なプロセッサが持つようなキャッシュメモリを持ちません。GPUが対象とするグラフィック処理では、大きなデータに対して少しずつ処理を行うことが多いため、何度も参照する小さなデータをキャッシュする、というのはあまり意味がないためです。
もっとも、データをキャッシュすることにあまり意味がないといっても、メインメモリへのアクセスには数百サイクルの時間が必要だという点は変わりません。キャッシュメモリを持つプロセッサでは、参照するデータをあらかじめプリフェッチする方法でメモリアクセスに必要な時間を隠すことが可能です。
しかし、キャッシュメモリを持たないT10は、プリフェッチしようにもそのデータを蓄えておく場所がないのです(一応16KBの高速なメモリを持っていますが、多数のスレッドで共有されるメモリであり十分なサイズとはいえません)。
つまり、T10では一般的なプロセッサとは違う方法で、数百サイクルのメモリアクセス時間を隠蔽する必要があります。そこでT10で採用されたのが数百個にもおよぶハードウェアスレッドというわけです。
あるスレッドがメインメモリへアクセスしたときに、そのスレッド以外に100個を超える数のスレッドが実行可能であったらどうなるでしょうか。100個のスレッドをそれぞれスレッド1〜100としましょう。
まず、1つ目のスレッド1がメモリへアクセスします。これには時間がかかるのでスレッド1は停止します。スレッド1が停止したので、実行可能なスレッド2が代わりに動きます。そして、スレッド2もやがてメモリにアクセスしてスレッド1と同じように停止します。
次に、スレッド3、スレッド4というように実行していき、スレッド100まで同じように実行して停止したとします。ここで、スレッド2〜スレッド100が、それぞれ数命令ほどメモリアクセス以外の処理を行なっていれば、この時点でスレッド1がメモリアクセスを行ってから数百サイクルが経過したことになります。
メインメモリへのアクセスに必要な時間は数百サイクル程度なので、このスレッド100が停止した時点でスレッド1はメモリアクセスを完了しており、再び実行可能状態になっているのです。
ここで重要なことは、スレッド1がメモリアクセスを行って停止してから再開するまで、プロセッサはほかの実行可能なスレッドの処理を行っており、一度も処理を停止していないということです。
つまり、数百個ものスレッドを同時実行できれば、キャッシュやローカルストレージがない場合でも、プロセッサが停止する無駄な時間をなくすことができるのです。キャッシュやローカルストレージのような巨大なメモリをプロセッサ内に持つ必要がなくなれば、その分多くの実行ユニットをプロセッサ内部に持つことができ、演算性能をさらに高めることができます。
T10というのは、単にプロセッサをたくさん並べた並列プロセッサだというだけでなく、演算性能を高めるためにメモリ構成も並列実行に特化したプロセッサであるといえるでしょう。
Intel Larrabee
最後に、今後現れるであろうプロセッサの代表として、Larrabeeを見てみましょう。
Larrabeeは、Intelが開発しているGPUです。名目上はGPUとなっていますが、その実体は通常のPCに積まれているプロセッサと同じx86プロセッサであり、一般的なプロセッサと同じ機能を持ったプロセッサです。
2009年8月現在、Larrabeeの詳細についてはまだ明らかになっていませんが、公開されている情報から、いくつかの特徴を知ることができます(公開されている情報については、WikipediaのLarrabeeの項を参照するのが手っ取り早いでしょう)。
現在公開されているLarrabeeの特徴のうち、並列に関するものについては、以下の3点が既存のx86プロセッサと比べて大きく変わっている点です。
- 16コア程度のマルチコア
- LRBと呼ばれる512bit(SSEと比べて4倍)の長さを持つSIMD
- 4つのハードウェアスレッド
このうちSIMD演算であるLRBniについては、既存のプロセッサ上で動作する互換ライブラリがIntelより公開されており、そのインターフェイス使って実際にプログラミングすることが可能になっています。
例えば、第1回で紹介したArrayのインクリメントプログラムは、リスト3のように書くことができます。
/*
* Array のインクリメント(LRB版)
*/
#include <stdio.h>
#include <lrb_prototype_primitives.inl>
#include <stdlib.h>
#define N 100000
int main (int argc, char *argv[])
{
int i;
int *rootBuf;
_M512I *vBuf;
_M512I v1;
rootBuf = (int *)malloc(N * sizeof(int));
vBuf = (_M512I*)rootBuf;
v1 = _mm512_set_1to16_pi(1);
/* Initialize */
for(i=0;i<N;i++){
rootBuf[i] = i;
}
for (i=0; i<N/16; i++) {
vBuf[i] = _mm512_add_pi(vBuf[i], v1);
}
free(rootBuf);
}このプログラムの性能は実際どのくらいになるのか。また、16コアものマルチコアを動作させるプログラムは一体どのように書くのか。続報が期待されます。
適材適所という考え方
以上、2回に渡って今日の並列ハードウェアと、その実装について見てきました。ひとことに並列といっても、さまざまな背景とそれにあわせた実装があることが確認できたことと思います。
ここにはいろいろなトレードオフがあるため、並列処理を行う場合には問題にあわせて適切なハードウェアを選択する必要があります。極端な例を挙げると、まったく並列性がなく全処理に依存があるような場合は、1命令あたりのレイテンシの短いx86が有利だと考えられますし、逆にまったく依存性がなく完全に並列実行できる場合は、演算性能、メモリバンド幅の大きいGPUが有利であるといえるでしょう。
そして、ハードウェアを選択したら、そのハードウェアに適切なプログラミングを行う必要があります。今回見てきたとおり、並列時代のハードウェアは既存のプロセッサではあまり見られない特徴的な構造をしているものが多いため、ソフトウェアもそれに最適なものにする必要があるのです。
というわけで並列化の時代には、ハードウェア、アルゴリズム、プログラミングの方法を適切に選択する必要があり、そのためにもハードウェアについてこれまで以上に知る必要があります、という話でした。
次回は「並列処理プログラミング」と題して、並列プログラムの書きかたについて解説する予定です。では、また次回までごきげんよう!
3/3 |
| Index | |
| プロセッサ別に見る並列アーキテクチャ | |
| Page1 実際の並列プロセッサの特徴を知る Intel Core i7 |
|
| Page2 Cell Broadband Engine |
|
| Page3 NVIDIA Tesla 10 Intel Larrabee 適材適所という考え方 |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





