プロが教える、クラウドインフラのトラブルシューティング「4つの原則」とは:「クラウドだからお手上げ」とは言っていられない(2/2 ページ)
クラウドインフラはオンプレミス環境と比べて複雑になりがちで、トラブルの原因特定に時間がかかることが多い。では、どういった点に注意してトラブルに対応していけばいいのか。
順序よく調査して影響範囲を明らかにする
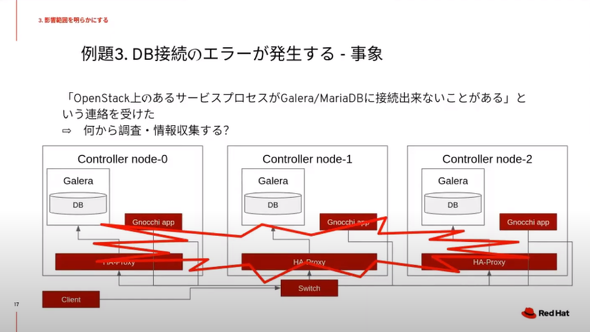
次の例は、「データベース(DB)接続でエラーが発生する」──OpenStack上のあるサービスプロセスで、複数のノードに展開され「Galera DB」「Maria DB」に接続できないことがあるという事象だ。井川氏は次のように語る。

「最初に、問題の発生しているノードを特定する。ハードウェアとソフトウェアの両方に多くの被疑箇所があるため、切り分けの順番が重要になる。まずは頻繁に発生している問題から調査するのが効率的だ。そこから、次にどの通信に問題が発生しているのかをチェックする」
続いて、障害発生時のログから、クライアントやサーバのプロセス稼働状況を見る。問題が継続している場合には、実際にアクセスして状況を確認すればよい。ノードの負荷状況から、パケットドロップなどが発生していないかどうかも確認する。「リソース使用量が高騰していないかどうか」「ディスク負荷の状況はどうか」という情報をチェックする。ここでポイントとなるのは、次に解説する日々の監視だ。
リソース監視を怠らない
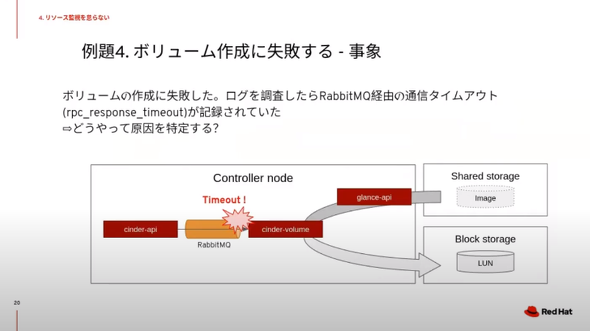
最後の例は「ボリュームの作成に失敗する」というものだ。さまざまな原因が考えられるが、今回はOpenStackのメッセージキューイングに利用する「RabbitMQ」経由で通信タイムアウト(rpc_response_timeout)が記録されていたとする。
タイムアウトを調査するときには「どのような処理で発生したのか」「何を待っている状況なのか」「どんな原因か考えられるか」という点を整理する。
クラウドインフラのような分散システムは、各システムとのやりとりに時間がかかることからタイムアウトを設定しているケースが多いという。そのため「よくあるタイムアウトの原因」を知っておくことも重要だ。
「タイムアウトはログに記録されるが、裏側で実行されているさまざまな処理を把握して、遅延の原因を追跡することは困難だ。重要なのは、ノードの負荷状況を継続的に記録しておくこと。これは、タイムアウトが発生した瞬間にリソース消費が増えていないかどうかを比較するため。特に、ディスクの負荷は重大なトラブルを引き起こすことがある」(井川氏)
誤ったトラブルシュートは避ける
梶波氏と井川氏によれば、「トラブルシューティング論」は奥深く、4つの原則で全てを網羅できないケースも多いという。そこで、両氏の経験から得られた幾つかのTipsについても紹介する。
データベースの直接編集は最後の手段にする
編集を誤ると新しい不具合を生むことになる。
ログをよく見る
「よく分からないから」「英語が苦手なので」とよく読まないと見逃すこともある。重要な情報が記載されているため、前後を含めてしっかり確認したい。
障害が発生している対象を確認する
確認する対象が間違っていると原因がつかめず時間ばかりかかる。
回避策が見つかっても評価環境でしっかりテストをする
コード上は問題ないと思っていても、予想外の事象が発生する可能性もある。慎重さも必要。
ハードウェア故障も考慮する
クラウドインフラもハードウェアの上で動いている。
トラブルシュートでは、GUIよりもCLIが向いている
GUIはとっつきやすいが、手順の再現や作業の繰り返しには不向きな場合もある。
井川氏は最後に「トラブルシューティングは決して容易ではないため、4つの原則を基に効率化していくことが重要だ。幾つかのTipsを含めて、トラブルシューティングのノウハウを蓄積、整理し、将来の運用に生かしていくべきだ」とまとめた。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 「技術的負債」が組織やエンジニアに与える影響とは?
「技術的負債」が組織やエンジニアに与える影響とは?
The Linux Foundation Japanは、『技術的負債とオープンソース開発』の日本語訳を公開した。技術的負債について、「ソフトウェア開発時にメインブランチからの逸脱によって発生したソースコードの保守コスト」と説明している。 代替可能なエンジニアのポストコロナ生き残り術
代替可能なエンジニアのポストコロナ生き残り術
ポストコロナのIT業界とエンジニアの生き残り術を模索する特集「ポストコロナのIT業界サバイバル術」。第4弾は、エンジニアの生き残り戦略です。 Uptime.com、2020年上半期のWebサーバダウンタイムレポートを発表
Uptime.com、2020年上半期のWebサーバダウンタイムレポートを発表
Uptime.comは、2020年上半期に世界6000以上の主要Webサイトで発生した障害やダウンタイムの状況などを業種別にまとめたレポートを発表した。