リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(1)(2/2 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。初回は全体的なアーキテクチャ、採用技術、開発体制について。
Qassの特徴的な要素の概要
この他、Qassは以下のような特徴的な要素を持っています(それぞれの詳細は後の連載で紹介します)。
機械学習による自己成長モデル
カスタマーが求める情報には季節性やトレンド性があり、これを即座に検索基盤に反映することは機会損失の防止につながります。
Qassでは検索クエリのログからカスタマー行動の変化を検出し、CVR(Conversion Rate)やCTR(Click Through Rate)、予測モデルに基づく検索結果順の最適化を実現しています。
また、新語や未知語の読み、単語間の共起率などから機械学習することで、辞書関連の運用コストを大幅に削減すると同時に適合率の向上を図っています。
検索行動分析に基づくサジェスト
前述した機械学習にも関連しますが、サジェスト用のインデックスは日々の検索ログを分析し、その結果をベースに作っています。
例えば「ようかい」と入力されたら以下のように人気のカテゴリ順にサジェストを表出するようにしています。
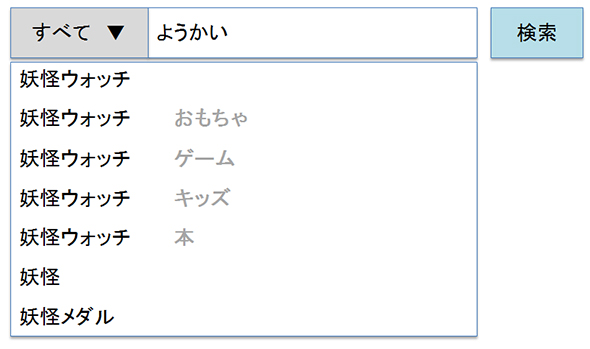
並び順は検索回数と結果数をベースにスコア値を算出していて、「ようかい」と入力する人は、下記のような行動を反映しているものになります。
ジャンル:「すべて」→「おもちゃ」→「ゲーム」→「キッズ」→「本」の順で「妖怪ウォッチ」を検索するケースが多い
サジェストインデックスは最低1日1回、原稿のライフサイクルが短い場合は数時間単位で作り直していて、頻繁に作り直すことでカスタマーの購入意欲に即座に追従し、機会損失を防止しています。
カスタマー行動の可視化
カスタマーがどういうワードで、ジャンルで、こだわり条件で検索しているか。機械だけではなく、われわれ人間側も検索行動を把握することは、事業を拡大するためだけではなく、検索の機能性を拡張するためにも非常に重要な要素です。
Qassでは、検索クエリログをHadoop環境に流し込んでさまざまな側面から集計し、その結果をログ解析アプリケーションである「Kibana」を使って可視化しています。

可視化軸の一例としては、下記があります。
- サジェスト選択ワードランキング
- 県別サジェスト選択率チャート
- 検索ワード、ゼロマッチワードのランキングとパターン傾向
サジェストがどのように使われているのか、どういうワード(パターン)のサジェストが好まれているのかを可視化し、カスタマー行動に合わせたサジェスト表出アルゴリズムに改修した結果、全体的には約3倍の選択率向上、地域によっては7倍近くの向上を実現しました。
ジャンル推定による検索結果の並び順最適化
サジェストのジャンル分析と可視化から得た事例をもう一つ紹介します。
フリーワード検索においては、カスタマーはジャンルを選択しないケースが非常に多いことが分かっています。「妖怪ウォッチ」のようにある程度商品が特定される場合はいいのですが、ブランド名や「時計」などで検索した場合は人気や売れ筋が考慮されない、カスタマーにうれしくない並び順となってしまいます。
そこで、ジャンル分析を検索結果の並び順にも適用し、どのジャンルに属する商品をより上位に表出すべきかをQass内で推定して検索クエリを動的に書き換え、より最適な結果となるようにしています。

開発体制と開発プロセス
筆者が所属する検索ユニットは複数組織のメンバーで構成されていますが、アプリ、インフラといったロールベースではなく、サービスごとのミッションベース、そして得意領域の異なる最小限のエンジニアでチームを編成しています(3〜5人体制が最も多いです)。

少数メンバーで編成することでメンバー間の密なコミュニケーションを促し、スピード感のある自律した意思決定を推進しています。開発サイクルはチームによって異なりますが、1週、2週、4週のいずれかでタイムボックスを区切って、エンハンス開発とA/Bテストを繰り返しています。
検索基盤はマッチングビジネスを展開するリクルートにとって欠かせない技術要素。従って、事業接点はとても多く、エンハンス開発のスピード感が求められるのです。
本連載では、こうしたQassの特性を一つ一つ紹介していきます。次回は検索結果の品質向上アプローチについて解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
ブームだったHadoop。でも実際にはアーリーアダプター以外には、扱いにくくて普及が進まないのが現状だ。その課題に幾つかの解決策が出てきた。転換期を迎えるHadoopをめぐる状況を整理しよう。 いまさら聞けないHadoopとテキストマイニング入門
いまさら聞けないHadoopとテキストマイニング入門
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します 検索エンジンの常識をApache Solrで身につける
検索エンジンの常識をApache Solrで身につける
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載 全文検索エンジン「Lucene.Net」を使う
全文検索エンジン「Lucene.Net」を使う
サイト構築などで使用できる検索エンジンをVBで活用。日本語アナライザを用いたインデックス作成から検索アプリ作成まで。- クックパッド、グリー、ぐるなび、CROOZは検索技術をどう使っているのか:検索技術を使うなら知ってないと損する6つのこと
ソーシャルアプリなど大規模Webサービスや企業内システムでも欠かせない検索技術のまとめ - Namazuによる全文検索システムの導入
サーバに集積した情報を再利用するには全文検索システムが必要だ。Namazuのインストールから設定、WordやExcelファイルのサポート方法、効果的な運用方法までを解説する